
زمان تخمینی مطالعه: 8 دقیقه
ویژگیهای موجود در تراشهها، سیستمها و نرمافزار، GPUهای انویدیا را برای یادگیری ماشینی با عملکرد و کارایی که میلیونها نفر از آن لذت میبرند، ایدهآل میسازد. GPUها عناصر کمیاب در هوش مصنوعی نامیده میشوند، زیرا پایهای برای عصر هوش مصنوعی مولد امروزی هستند. سه دلیل فنی، و موضوعات دیگر ورای این ادعا هستند و آن را توضیح میدهند. هر دلیل دارای جنبههای متعددی است که ارزش بررسی را دارد، اما در سطحی بالا میتوان گفت که:
- پردازندههای گرافیکی از پردازش موازی استفاده میکنند.
- سیستمهای GPU تا مقیاس ابررایانهها قابل ارتقاع هستند.
- پشته نرم افزار GPUها برای هوش مصنوعی گسترده و عمیق است.
در نتیجه میتوان گفت که GPUها محاسبات فنی را سریعتر و با بهره وری انرژی بیشتر از CPUها انجام میدهند. این بدان معناست که آنها عملکرد پیشرو را برای آموزش و استنتاج هوش مصنوعی و همچنین دستاوردهایی در طیف گستردهای از برنامههای کاربردی که از محاسبات تسریع شده استفاده میکنند، ارائه میدهند.
گروه هوش مصنوعی انسان محور استنفورد در گزارش اخیر خود در مورد هوش مصنوعی، چنین بیان میکند که: عملکرد GPUها “تقریبا 7000 برابر” از سال 2003 افزایش یافته است و قیمت هر عملکرد “5600 برابر بیشتر” است.
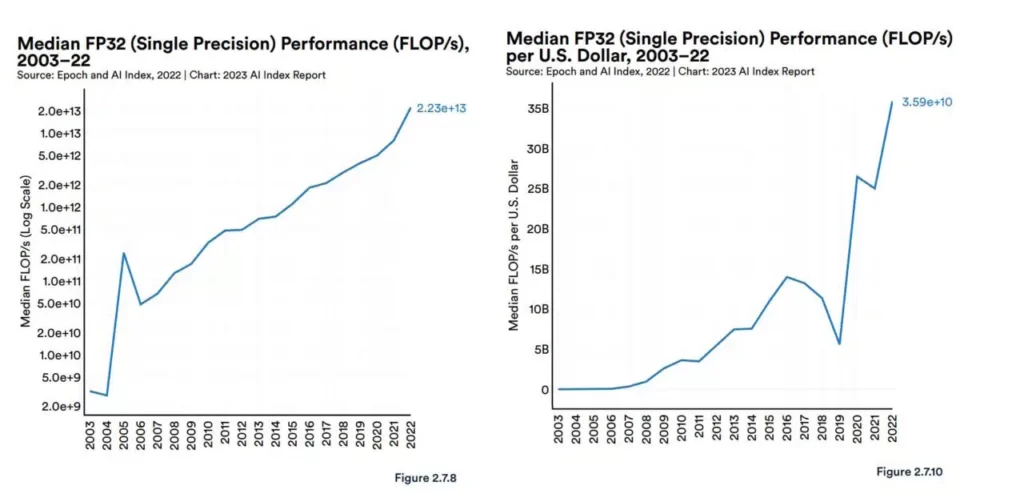
این گزارش همچنین به تحلیل Epoch، یک گروه تحقیقاتی مستقل که پیشرفتهای هوش مصنوعی را اندازهگیری و پیشبینی میکند، استناد کرده است. به گفته Epoch “پردازندههای گرافیکی پلتفرم محاسباتی غالب برای تسریع بارهای کاری یادگیری ماشینی هستند و اکثر (اگر نه همه) از بزرگترین مدلها در پنج سال گذشته بر روی پردازندههای گرافیکی آموزش دیدهاند.”
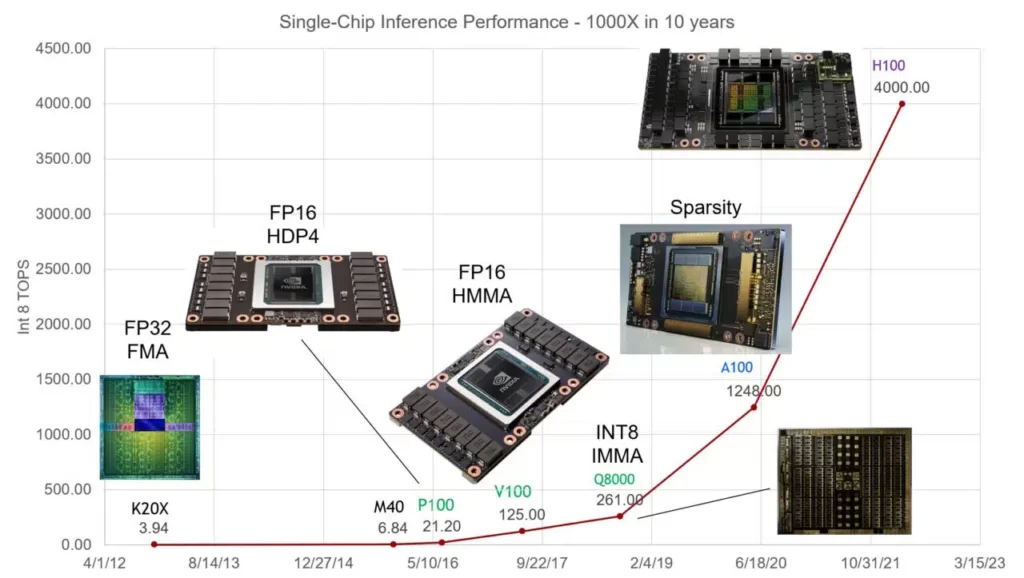
یک مطالعه در سال 2020 که فناوری هوش مصنوعی را برای دولت ایالات متحده ارزیابی میکرد، به نتایج مشابهی دست یافته است.در این بیانیه آمده است: «ما انتظار داریم تراشههای هوش مصنوعی یک تا سه مرتبه مقرون به صرفهتر از CPUهای پیشرو در محاسبه هزینههای تولید و عملیاتی باشند». بیل دالی، دانشمند ارشد این شرکت در سخنرانی اصلی در Hot Chips، گردهمایی سالانه مهندسین نیمه هادیها و سیستمها، گفت: پردازندههای گرافیکی NVIDIA در ده سال گذشته 1000 برابر قدرت استنتاج هوش مصنوعی را افزایش دادهاند.
پدیدهای به نام ChatGPT
سیستم ChatGPT یک مثال قدرتمند از است که چگونه GPUها برای هوش مصنوعی ابزاری عالی هستند. مدل زبان بزرگ (LLM) که بر روی هزاران پردازنده گرافیکی NVIDIA آموزش دیده و اجرا میشود، سرویسهای هوش مصنوعی مولد مورد استفاده بیش از 100 میلیون نفر را اجرا میکند. از زمان عرضه در سال 2018، MLPerf، معیار استاندارد صنعتی برای هوش مصنوعی، اعدادی را ارائه کرده است که عملکرد پیشرو پردازندههای گرافیکی NVIDIA را هم در آموزش و هم در استنباط هوش مصنوعی نشان میدهد.
به عنوان مثال، NVIDIA Grace Hopper Superchips آخرین دور آزمایشهای استنتاج را انجام داد. NVIDIA TensorRT-LLM، نرم افزار استنتاجی که پس از آن آزمایش منتشر شد، تا 8 برابر افزایش عملکرد و بیش از 5 برابر کاهش مصرف انرژی و هزینه کل مالکیت را ارائه میدهد. در واقع، پردازندههای گرافیکی NVIDIA از زمان انتشار این معیار در سال 2019، برنده تمام مراحل آموزش MLPerf و تستهای استنتاج شدهاند. در ماه فوریه سال 2023، پردازندههای گرافیکی NVIDIA نتایج برجستهای را برای استنباط ارائه کردند و هزاران استنتاج در ثانیه را در مورد پر تقاضاترین مدلها در معیار STAC-ML Markets ارائه کردند، که یک معیار کلیدی عملکرد فناوری برای صنعت خدمات مالی است.
یک تیم مهندسی نرمافزار RedHat به طور خلاصه در وبلاگ خود اینگونه بیان میکنند که: «GPUها پایه و اساس هوش مصنوعی شدهاند».
هستههای Tensor تیون شده
با گذشت زمان، مهندسان NVIDIA هستههای GPU را با نیازهای در حال تکامل مدلهای هوش مصنوعی تنظیم کردهاند. جدیدترین پردازندههای گرافیکی شامل هستههای Tensor هستند که 60 برابر قدرتمندتر از طراحیهای نسل اول برای پردازش شبکههای عصبی ریاضی ماتریسی هستند. علاوه بر این، پردازندههای گرافیکی NVIDIA Hopper Tensor Core دارای یک موتور ترانسفورماتور هستند که میتواند به طور خودکار دقت مطلوب مورد نیاز برای پردازش مدلهای ترانسفورماتور را تنظیم کند، کلاس شبکههای عصبی که هوش مصنوعی مولد را ایجاد کردند.
در طول مسیر، هر نسل GPU حافظه بیشتری را جمعآوری کرده و تکنیکهای بهینهسازی شدهای را برای ذخیره کل مدل هوش مصنوعی در یک واحد پردازش گرافیکی یا مجموعهای از پردازندههای گرافیکی دارد.
رشد مدلها، گسترش سیستمها
پیچیدگی مدلهای هوش مصنوعی 10 برابر در هر سال افزایش یافته است. پیشرفتهترین مدل LLM امروزی که GPT4 است، بیش از یک تریلیون پارامتر را در خود جای داده است که معیاری از چگالی ریاضی آن است. این در مقایسه با کمتر از 100 میلیون پارامتر برای یک LLM محبوب در سال 2018 است.
سیستمهای GPU با انجام این چالش همگام شدهاند. آنها به لطف اتصالات سریع NVLink و شبکههای کوانتومی اینفینیباند NVIDIA به ابررایانهها میرسند. به عنوان مثال، DGX GH200، یک ابر رایانه هوش مصنوعی با حافظه بزرگ، حداکثر 256 سوپرتراشه NVIDIA GH200 Grace Hopper را در یک واحد پردازش گرافیکی در اندازه مرکز داده با 144 ترابایت حافظه مشترک ترکیب میکند. هر سوپرتراشه GH200 یک سرور واحد با 72 هسته CPU Arm Neoverse و چهار پتافلاپ عملکرد هوش مصنوعی است. پیکربندی جدید سیستمهای Grace Hopper چهار طرفه، 288 هسته بازو و 16 پتافلاپ عملکرد هوش مصنوعی با حداکثر 2.3 ترابایت حافظه پرسرعت را در یک گره محاسباتی واحد قرار میدهد. و پردازندههای گرافیکی NVIDIA H200 Tensor Core که در ماه نوامبر معرفی شدند تا 288 گیگابایت از آخرین فناوری حافظه HBM3e را در خود جای دادهاند.
نرم افزار پیشروی این قلمرو
اقیانوس در حال گسترش نرمافزار GPUها از سال 2007 تکامل یافته است تا همه جنبههای هوش مصنوعی، از ویژگیهای فناوری عمیق گرفته تا برنامههای کاربردی سطح بالا را فعال کند. پلتفرم NVIDIA AI شامل صدها کتابخانه نرم افزاری و برنامه است. زبان برنامهنویسی CUDA و کتابخانه cuDNN-X برای یادگیری عمیق، پایهای را فراهم میکنند که توسعهدهندگان نرمافزاری مانند NVIDIA NeMo را ایجاد کردهاند، چارچوبی که به کاربران اجازه میدهد تا مدلهای هوش مصنوعی مولدی خود را بسازند، سفارشی کنند و استنتاج کنند.
بسیاری از این عناصر بهعنوان نرمافزار متنباز، که جزء اصلی توسعهدهندگان نرمافزار هستند، در دسترس هستند. بیش از صد مورد از آنها در پلتفرم NVIDIA AI Enterprise برای شرکتهایی که به امنیت و پشتیبانی کامل نیاز دارند، بسته بندی شده اند. به طور فزایندهای، آنها همچنین از ارائه دهندگان خدمات ابری اصلی به عنوان API و خدمات در NVIDIA DGX Cloud در دسترس هستند. SteerLM، یکی از آخرین بهروزرسانیهای نرمافزار هوش مصنوعی برای پردازندههای گرافیکی NVIDIA، به کاربران اجازه میدهد مدلها را در حین استنتاج تنظیم کنند.
شروع داستان
داستان موفقیت این تکنولوژی به مقالهای در سال 2008 از اندرو نگ(Andrew Ng)، پیشگام هوش مصنوعی، که در آن زمان محقق دانشگاه استنفورد بود، برمیگردد. تیم سه نفره او با استفاده از دو پردازنده گرافیکی NVIDIA GeForce GTX 280 به سرعت 70 برابری نسبت به پردازندههایی که یک مدل هوش مصنوعی با 100 میلیون پارامتر را پردازش میکنند، دست یافتند و کارهایی را که قبلاً چندین هفته طول میکشید در یک روز به پایان رساندند. آنها گزارش دادند: «پردازندههای گرافیکی مدرن بسیار از قابلیتهای محاسباتی پردازندههای چند هستهای پیشی میگیرند و پتانسیل ایجاد انقلابی در کاربرد روشهای یادگیری عمیق بدون نظارت را دارند.

در سخنرانی TED در سال 2015 در کنفرانس GPU اندویدیا آقای Ng توضیح داد که چگونه به استفاده از پردازندههای گرافیکی بیشتر برای ارتقای کار خود ادامه داد و مدلهای بزرگتری را در Google Brain و Baidu اجرا کرد. بعدها، او به تأسیس Coursera، یک پلتفرم آموزش آنلاین کمک کرد که در آن به صدها هزار دانشآموز هوش مصنوعی آموزش داد. آقای Ng، جف هینتون را به عنوان یکی از پدرخواندههای هوش مصنوعی مدرن قرار میدهد. او در سخنرانی GTC گفت: “به یاد دارم که به دیدار جف هینتون رفتم و گفت CUDA را بررسی کنید، فکر میکنم میتواند به ساخت شبکههای عصبی بزرگتر کمک کند.”
واقعا مطلب جالب و کاملی بود
دست مریزاد
اولا با تشکر از حسن توجه جنابعلی به مطالب سایت. دوما ما وظیفه خودمون می دونیم.
تیم پشتیبانی الکتروهایو
با سلام و عرض ادب
واقعا مطلب زیبا و کاملی بود
با تشکر از عنایت شما به مطالب سایت
تیم پشتیبانی الکتروهایو