
زمان تخمینی مطالعه: 10 دقیقه
مدلهای زبان بینایی (Vision language Models) نوعی مدل هوش مصنوعی هستند که قابلیتهای بینایی کامپیوتری (CV) و پردازش زبان طبیعی (NLP) را ترکیب میکنند. این مدلها برای درک و تولید متن در مورد تصاویر طراحی شدهاند و شکاف بین اطلاعات بصری و توضیحات زبان طبیعی را پر میکنند.
VLM ها میتوانند وظایف مختلفی را انجام دهند، از جمله شرح تصاویر (تولید توضیحات برای تصاویر)، پاسخگویی به سؤالات بصری (پاسخ به سؤالات در مورد تصاویر)، و تطبیق تصویر-متن (پیدا کردن شباهت بین تصاویر و توضیحات متن). مدلهای زبان بینایی معمولاً بر روی مجموعه دادههای بزرگی که حاوی تصاویر جفت و حاشیهنویسی متن هستند، آموزش میبینند و به مدل اجازه میدهد تا ارتباط ویژگیهای بصری را با عبارات زبانی یاد بگیرد. یکی از چالشهای کلیدی در توسعه VLM ها، ادغام هر دو روش بصری و متنی به شیوهای منسجم و موثر است. محققان برای دستیابی به این یکپارچگی از تکنیکهایی مانند ادغام چند وجهی استفاده میکنند که در آن اطلاعات بصری و متنی در مراحل مختلف معماری مدل ترکیب میشوند.
VLM ها در زمینههای متنوعی، از جمله تولید محتوا، دسترسی (به عنوان مثال، برای افراد کم بینا) و درک چندوجهی (به عنوان مثال، برای سیستمهای مستقلی که نیاز به درک تصاویر و متن دارند) کاربرد دارند. مدلهای زبان بینایی نشان دهنده پیشرفت قابل توجهی در فناوری هوش مصنوعی هستند و ماشینها را قادر میسازند تا دنیای بصری را بهتر درک کنند و با آن تعامل داشته باشند.
کاربردهای مدلهای زبان بینایی
مدلهای زبان بینایی (VLM) دارای کاربردهای متنوعی در دنیای واقعی و صنایع مختلف است. در اینجا بخش چند نمونه از این کاربردها آورده شده است:
- زیرنویس تصویر Image Captioning: در حالت کلی VLMها میتوانند توصیفهای تکمیلی را برای تصاویر ایجاد کنند و آنها را برای کاربردهایی مانند تولید محتوای رسانههای اجتماعی، برچسبگذاری خودکار تصویر، و افزایش دسترسی برای افراد کم بینا مفید سازند.
- پاسخ به سؤالات بصری (Visual Question Answering): VLMها میتوانند به سؤالات مربوط به تصاویر پاسخ دهند، کاربردهایی زیادی در ابزارهای آموزشی تعاملی، دستیاران مجازی برای پرس و جوهای مبتنی بر تصویر و موتورهای جستجوی تصویر پیشرفته دارد.
- ایجاد محتوا: از مدلهای زبان بینایی میتوان برای تولید محتوای جذاب برای بازاریابی، تبلیغات و داستان سرایی استفاده کرد. VLMها میتوانند به طور خودکار زیرنویسها، سرفصلها و سایر عناصر متنی را برای محتوای بصری تولید کنند.
- درک چندوجهی: VLMها میتوانند در درک و تفسیر محتوای چندوجهی، مانند ویدیوها، که در آن اطلاعات دیداری و شنیداری هر دو وجود دارد، کمک کننده باشند. این موضوع میتواند برای کاربردهایی مانند خلاصهسازی ویدیو و تعدیل محتوا مفید باشد.
- واقعیت مجازی و واقعیت افزوده: مدلهای زبان بینایی قادر است تا تجربیات واقعیت مجازی(VR) و واقعیت افزوده(AR) را با ارائه اطلاعات مرتبط با زمینه یا تولید عناصر تعاملی بر اساس ورودی بصری افزایش دهند.
- مراقبتهای بهداشتی: VLMها میتوانند در تجزیه و تحلیل تصاویر پزشکی، مانند شناسایی ناهنجاریها در اسکنهای پزشکی یا کمک به رادیولوژیستها در تشخیص با ارائه اطلاعات مرتبط بر اساس ورودیهای بصری، کمک کنند.
راهکارهای یادگیری
مدلهای زبان بینایی برای مدت طولانی موضوع مهمی برای تحقیق و مطالعه بوده است. محققان چندین استراتژی یادگیری را مورد بررسی قرار دادهاند که میتوانند برای بالا بردن اطمینان و تقویت یادگیری مدل مورد استفاده قرار گیرند. برخی از این رویکردها به صورت نهایی هستند و در جهت ادغام ویژگیهای متنی و بصری کار میکنند، در حالی که برخی دیگر متن و تصویر را بهعنوان روشهای جداگانه در نظر میگیرند. در ادامه نگاهی عمیق به برخی از محبوبترین استراتژیپهای یادگیری خواهیم انداخت.
– یادگیری متضاد Contrastive Learning
یادگیری متضاد بر آموزش مدل در مورد تفاوت بین ورودیهای مشابه و متفاوت متکی است. ایده اصلی در روش یادگیری متضاد این است که مدل را با ورودیها به صورت جفت ارائه کنیم به این صورت که جفتهای مشابه جفتهای مثبت و جفتهای غیرمشابه به عنوان جفتهای منفی شناخته میشوند. در این حالت مدل یاد میگیرد که نمایشهای معناداری از جفت ورودی را استخراج کند و آنها را در فضایی با ابعاد پایینتر نمایش دهد. با این روش مدل سعی میکند بازنماییهای جفت مشابه را به یکدیگر نزدیکتر کند و در نتیجه نمایشهای غیرمشابه دور از هم پیشبینی میشوند.
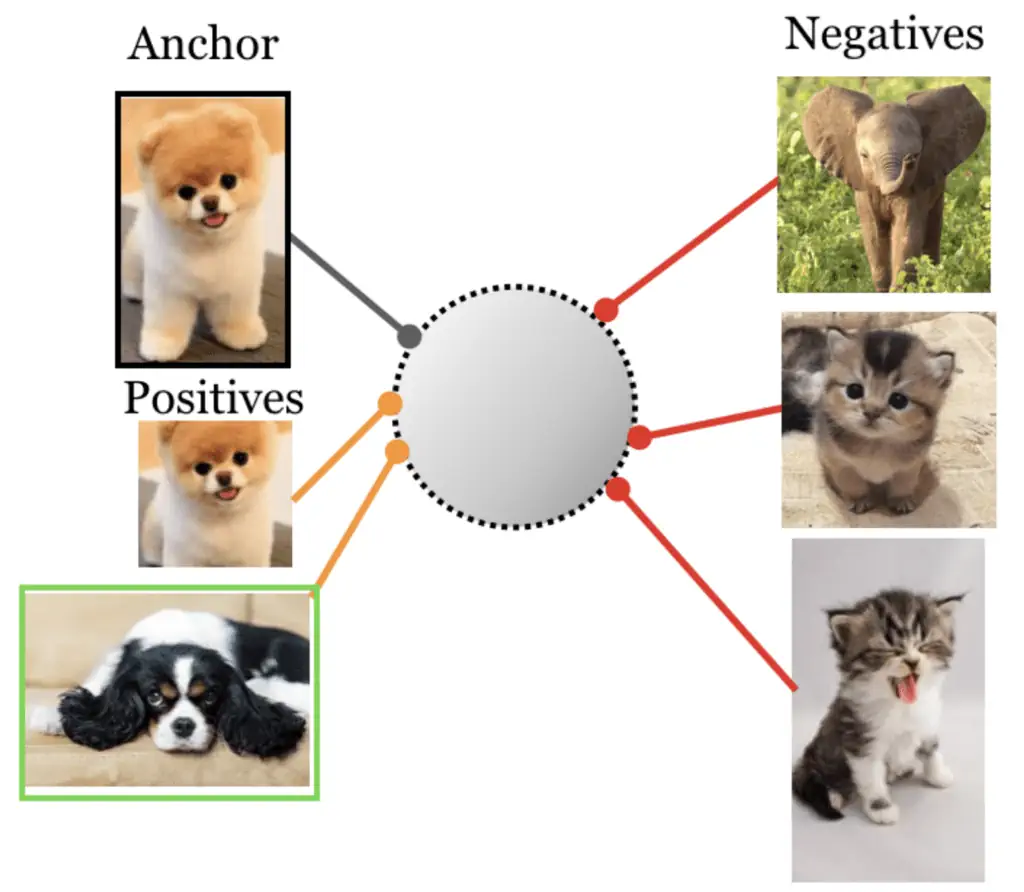
فواصل بین پیشبینیها را میتوان با استفاده از اکتشافات(فواصل) منهتن و اقلیدسی اندازهگیری کرد. یادگیری متضاد را میتوان به صورت با نظارت، نیمه نظارتی یا خود نظارت انجام داد. این موضوع نیاز به مجموعه دادههای حاشیهنویسی با اندازه بزرگ را کاهش میدهد.
– الگوریتم PrefixLM
مدلسازی زبان پیشوند (PrefixLM) تکنیکی است که از یک پیشوند با طول ثابت دنبالهای از نشانهها (مانند کلمات یا کاراکترها) برای پیشبینی نشانه بعدی در دنباله استفاده میکند. در زمینه آموزش مدلهای زبان بینایی، از پیشوند برای ارائه زمینه به مدل زبان استفاده میشود تا بتواند زیرنویسهای دقیق و آموزندهتری برای تصاویر ایجاد کند.
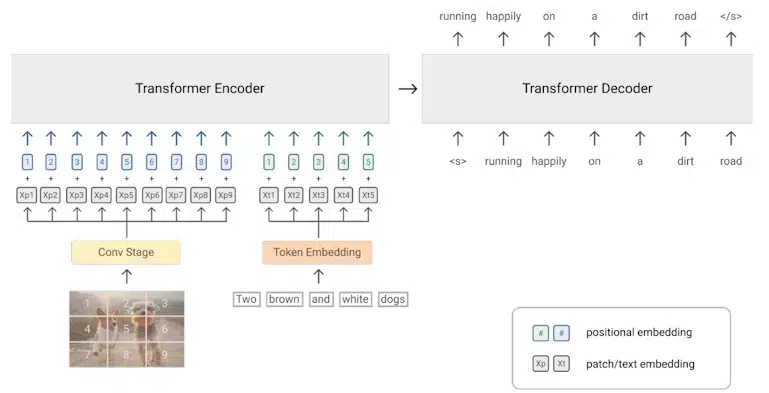
در این تکنیک ایده این است که پیشوند یک نقطه شروع برای مدل زبان ارائه میکند و به آن کمک میکند تا در هنگام ایجاد عنوان روی جنبههای مرتبط تصویر تمرکز کند. با استفاده از پیشوندی که توصیف کننده تصویر است، مدل زبان میتواند زیرنویسهایی ایجاد کند که دقیقتر و آموزندهتر باشند و محتوا و زمینه تصویر را بهتر ثبت کنند.
– ترکیب چندوجهی با توجه متقاطع
در نهایت، برای توسعه یک مدل کاملاً تعمیمیافته که قادر به تکمیل وظایفی است که به اطلاعات بصری و متنی نیاز دارند، به مدلی نیاز داریم که بتواند تصاویر و متن را بهعنوان ورودی بگیرد و به طور مشترک هر دو را برای انجام کارها پردازش کند. این کار میتواند شامل پاسخ به سوال بصری، تشخیص اشیاء و تقسیمبندی معنایی باشد. مدل باید بتواند ویژگیهای بصری و متنی را جمعآوری کند و آنها را مطابق زمینه فعلی کند.
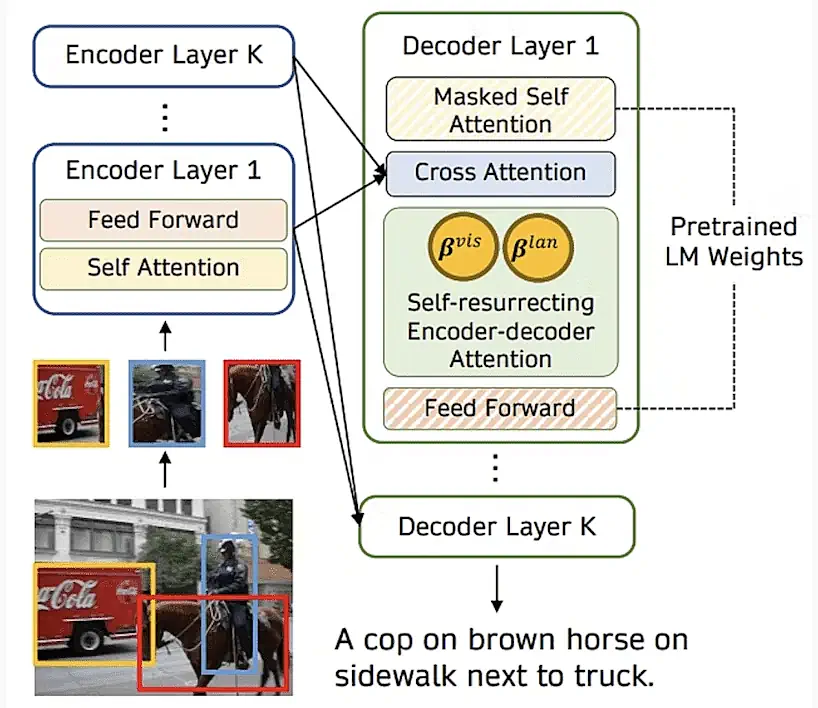
ادغام چندوجهی با توجه متقاطع تکنیکی است که به مدل اجازه میدهد تا این روابط را با ادغام اطلاعات بصری و زبانی به روشی که زمینه و ارتباط هر روش را در نظر میگیرد، یاد بگیرد. این تکنیک بدین صورت عمل میکند که ابتدا اطلاعات بصری و زبانی را با استفاده از رمزگذارهای جداگانه، مانند یک CNN برای اطلاعات بصری و یک ترانسفورماتور برای اطلاعات زبانی، رمزگذاری میکند. سپس نمایشهای رمزگذاریشده با استفاده از توجه متقاطع ترکیب میشوند، که به مدل اجازه میدهد تا ارتباط هر روش را بیاموزد و یک نمایش وزندار ایجاد کند که زمینه و ارتباط هر روش را در نظر میگیرد.
تحقیق در مورد مدلهای زبان بینایی
گرایشها به VLM با ظهور مدلهای زبانی بزرگ که قادر به پردازش پنجرههای زمینه بزرگ هستند به خوبی تثبیت شده و جذابیت قابلتوجهی پیدا کردهاند. مدلهای متن به تصویر، پل زدن بین نشانههای بصری و متنی را با مدلهای انتشاری(diffusion models) تسریع کردهاند. در این بخش بیایید نگاهی به برخی از اساسیترین آزمایشات تحقیقاتی برای تبدیل VLMها به واقعیت بیندازیم.
- CLIP: مدل CLIP (Contrastive Language-Image Pre-Training) با یادگیری بازنمایی قوی از تصاویر و متن کار میکند. این مدل بر روی یک مجموعه داده بزرگ از جفتهای تصویر-متن آموزش داده شده است، که در آن هر جفت از یک تصویر و یک عنوان متن مربوطه تشکیل شده است. این مدل از یک رمزگذار متن و رمزگذار تصویر برای تبدیل مجموعه دادههای بزرگ جفت تصویر-متن به جاسازی ویژگیهای مربوطه استفاده میکند. سپس الگوریتم مدل را آموزش میدهد تا یاد بگیرد که تلفات(loss) بین جفتهای جاسازی صحیح تصویر-متن را به حداقل برساند، و تلفات بین جفتهای نادرست را به حداکثر برساند. این مرحله قبل از آموزش است، و پس از تکمیل، این مدل میتواند برای ایجاد یک طبقهبندی کننده صفر شات(zero-shot) بر روی یک مجموعه داده بدون هیچ گونه آموزش صریح استفاده شود.
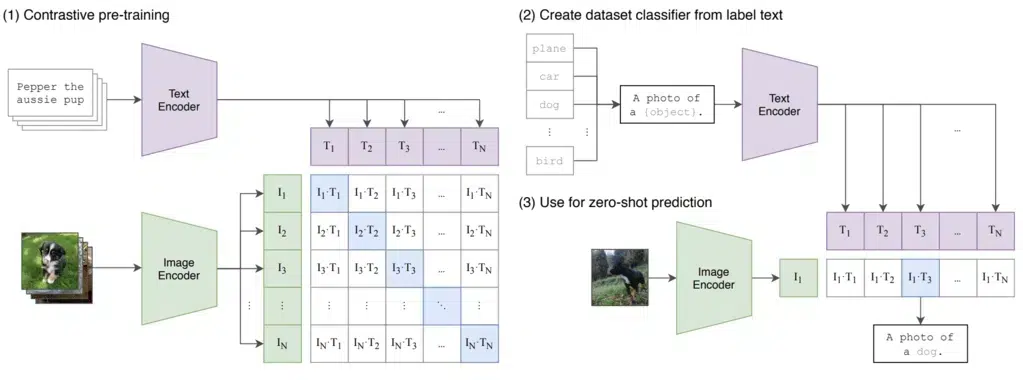
در مرحله آزمایش، مدل از کلاسهای مجموعه داده استفاده میکند تا یک عنوان ابتدایی مانند «عکسی از [object]» برای هر برچسب کلاس ایجاد کند. هر عنوان توسط رمزگذار متن پردازش میشود و تعبیه متنی آن به مجموعه جاسازیها اضافه میشود. به طور مشابه رمزگذار تصویر، تصویر ورودی را پردازش میکند تا جاسازی تصویر را ایجاد کند. از آنجایی که CLIP برای یافتن جاسازیهای جفت تصویر-متن مشابه از قبل آموزش داده شده است، تصویر جاسازی شده با مناسبترین جاسازی جفت میشود (کلاس مرتبط با این جاسازی به عنوان محتملترین طبقهبندی در نظر گرفته میشود). بنابراین، این مدل میتواند بدون صراحت در مجموعه دادههای آموزشی، شرح تصاویر را به شکلی آماده انجام دهد.
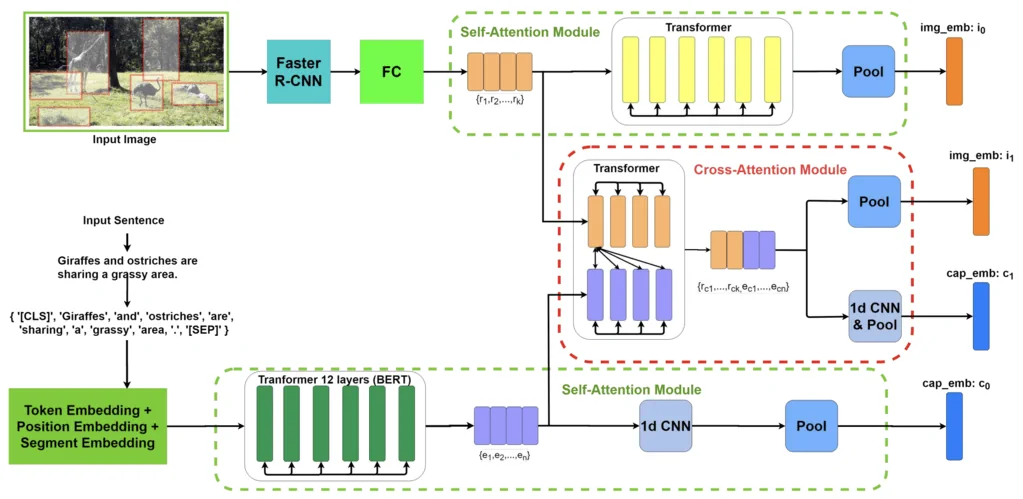
- شبکه توجه متقابل چند وجهی: مقاله این روش مدلی را پیشنهاد میکند که قادر به یافتن جفت تصویر و زیرنویس مناسب است. این مدل برای یافتن جفتهای متن و تصویر مشابه از نظر معنایی آموزش دیده است. این روش قصد دارد این تطابق را با جلب توجه بصری و توجه متنی و ترکیب آنها با یکدیگر برای انجام تمرینات مشترک انجام دهد. نوآوری کلیدی شبکههای توجه متقابل چند وجهی، استفاده از مکانیسمهای توجه متقابل برای یادگیری روابط بین روشهای مختلف است. توجه متقابل به مدل اجازه میدهد تا به طور انتخابی بر مرتبطترین بخشهای دادههای ورودی تمرکز کند و خروجی تولید کند که زمینه و ارتباط هر روش را در نظر میگیرد.
نتیجه گیری
تحقیقات پیرامون مدلهای زبان بینایی روز به روز بیشتر مورد توجه قرار میگیرد. این مدلها قادر به انجام وظایف بینایی کامپیوتر با استفاده از دستورالعملهای متنی ساده مانند نوشتن شرح تصویر، پاسخگویی بصری، تشخیص اشیاء و بخشبندی تصویر هستند. راهبردهای متعددی برای آموزش یک مدل زبان بینایی مانند یادگیری متضاد، مدلسازی زبان پیشوندی و ترکیب چند وجهی وجود دارد. این مدلها را میتوان در برنامههای مختلف دنیای واقعی مانند تولید محتوا و واقعیت مجازی استفاده کرد.