
زمان تخمینی مطالعه: 12 دقیقه
در این مقاله، شبکه عصبی کانولوشن (Convolutional Neural Network) را که یک عنصر کلیدی در بینایی کامپیوتری و پردازش تصویر است را بررسی خواهیم کرد. این مقاله برای تمامی افراد چه یک فرد مبتدی باشید و یا یک متخصص با تجربه میتواند مفید باشد. همچنین این مقاله اطلاعاتی در مورد مکانیک شبکههای عصبی مصنوعی و کاربردهای آنها را ارائه میدهد.
تاریخچه شبکه عصبی کانولوشن
شبکههای عصبی کانولوشنال (CNN) تکامل و پیچیدگی مستمری را پشت سر گذاشتهاند. این موضوع در دهه 1980 با توسعه LeNet توسط Yann LeCun آغاز شد. LeNet، که عمدتاً برای وظایف تشخیص رقم استفاده میشود، معماری اساسی را برای CNN ها ایجاد کرد. مدل معماری آن از لایههای کانولوشن، لایههای ادغام و لایههای کاملاً متصل تشکیل شده است.
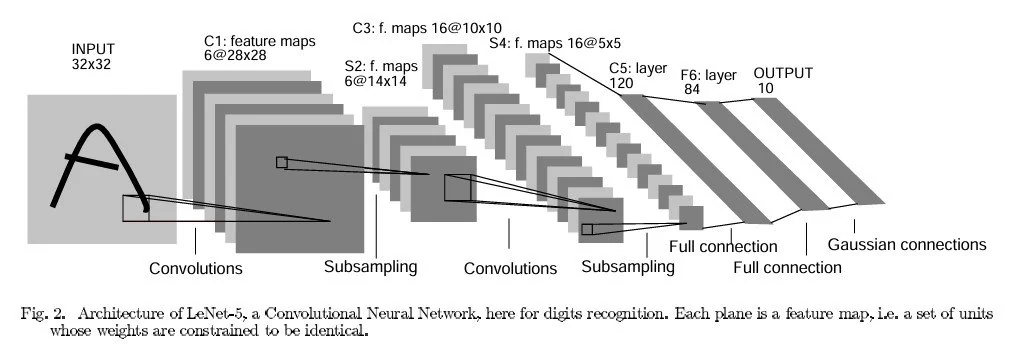
در سال 2012، معماری AlexNet، طراحی شده توسط Alex Krizhevsky، Ilya Sutskever و Geoffrey Hinton، با کاهش قابل توجه نرخ خطا، پیشرفتی را در چالش ImageNet رقم زد. موفقیت AlexNet به معماری عمیقتر و پیچیدهتر آن، استفاده از تابع فعالساز ReLU (واحد خطی اصلاحشده) بهعنوان یک تابع فعالسازی و اجرای لایههای حذف برای جلوگیری از برازش بیش از حد نسبت داده شد.
VGGNet که توسط Simonyan و Zisserman در سال 2014 معرفی شد، بر اهمیت عمق در معماری CNN از طریق شبکه 16-19 لایه CNN خود تأکید کرد. GoogleNet (یا Inception) مفهوم جدیدی از ماژولهای اولیه را به ارمغان آورد که محاسبات کارآمد و شبکههای عمیقتر را بدون افزایش قابل توجه پارامترها امکان پذیر میکند.
ResNet، که توسط Kaiming He و همکاران توسعه یافته، اتصالات باقیمانده را برای تسهیل آموزش شبکههای حتی عمیقتر معرفی کرد. این مدل با 152 لایه خود از عمق معماریهای قبلی پیشی گرفت.
نوآوریهای اخیر در طراحی CNN بر بهینهسازی کارایی و عملکرد شبکه تمرکز دارد. مقالات بینایی کامپیوتری مانند “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications” نوشته شده توسط Andrew G. Howard et al. و “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks” نوشته شده توسط Mingxing Tan و Quoc V. Le معماریهایی را پیشنهاد میکنند که دقت و کارایی محاسباتی را متعادل میکند. این موارد باعث میشود آنها برای کاربردهای دنیای واقعی، به ویژه در دستگاههایی با ظرفیت محاسباتی محدود، مناسب باشند.
Convolutional Neural Network ها در بینایی کامپیوتری مفهومی فراتر از طبقهبندی تصویر
CNN ها تأثیر عمیقی بر بینایی رایانهای گذاشتهاند که بسیار فراتر از طبقهبندی تصویر اولیه است. توانایی آنها در تفسیر دادههای بصری در تشخیص اشیاء، بخشبندی، تجزیه و تحلیل ویدئو و پردازش بلادرنگ بسیار مهم بوده است.
– تشخیص و تقسیمبندی اشیاء
در تشخیص اشیا، شبکههای عصبی CNN چندین شی را در یک تصویر شناسایی و مکانیابی میکنند. این کار پیچیدهتر از طبقهبندی است، زیرا شامل شناسایی اشیاء و تعیین مکان دقیق آنها میشود. معماری شبکه عصبی کانولوشنال مبتنی بر منطقه (R-CNN) و تکرارهای بعدی آن، Fast R-CNN و Faster R-CNN، در این امر مؤثر بوده است. این معماریها از ترکیبی از جستجوی انتخابی برای پیشنهاد مناطق و CNN ها برای طبقهبندی استفاده میکنند. بنابراین، دقت و سرعت تشخیص اشیاء به طور قابل توجهی بهبود مییابد.
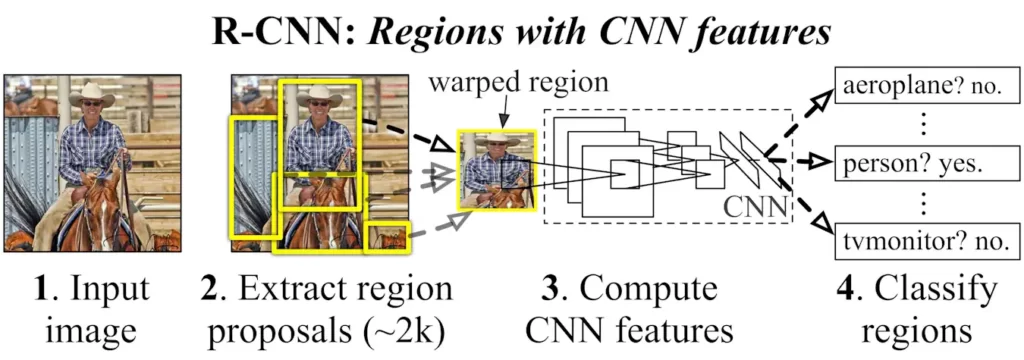
CNN ها پیشرفت مشابهی را در تقسیمبندی تصویر ممکن میکنند. این کار شامل تقسیم یک تصویر به بخشهایی برای مکانیابی و درک اشیاء در سطح پیکسل است. U-Net، یک معماری CNN برای تقسیمبندی تصاویر زیست پزشکی، یک نمونه بارز از این کاربرد است. طراحی منحصر به فرد U شکل آن شامل یک مسیر منقبض برای گرفتن زمینه و یک مسیر متقارن در حال گسترش برای مکانیابی دقیق است.
پیشرفت در تجزیه و تحلیل ویدئو و پردازش زمان واقعی
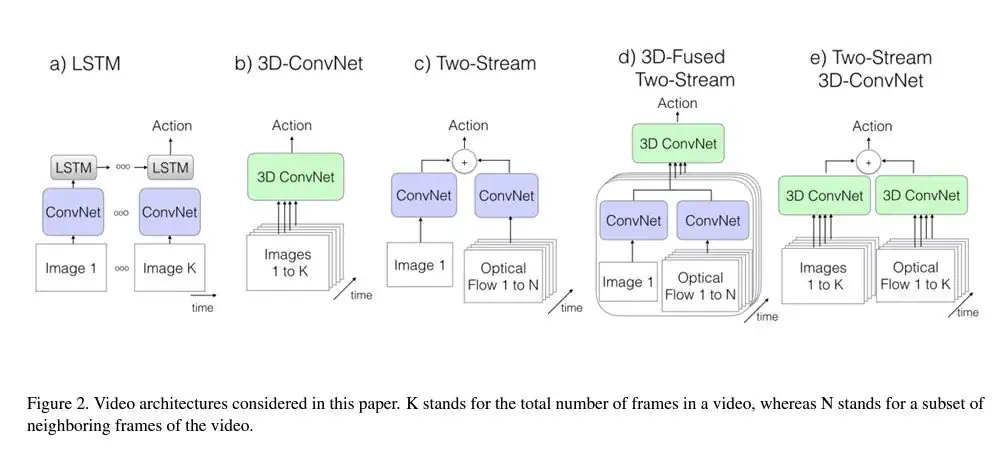
در کاربردهایی مانند تشخیص کنش و تشخیص ناهنجاری در ویدیوها، شبکه عصبی کانولوشن باید دینامیک زمانی و ویژگیهای مکانی را درک کنند. معماریهایی مانند شبکههای عصبی کانولوشنال سهبعدی (3D-CNN) پیچیدگی دو بعدی معمولی را به سه بعد گسترش میدهند. این موضوع به شبکه اجازه میدهد تا ویژگیهای مکانی و زمانی را بیاموزد. مقاله اخیر، Quo Vadis, Action Recognition? A New Model and the Kinetics» نوشته شده توسط João Carreira و Andrew Zisserman، مدل Inflated 3D ConvNet (I3D) را ارائه میکند که فیلترها و هستههای یک CNN دوبعدی را به سه بعدی تبدیل میکند. این کار به آن امکان میدهد تا ویژگیهای مکانی-زمانی را برای تشخیص عملکرد ویدیویی یاد بگیرد.
الگوریتمهای شبکه عصبی کانولوشن برای چالشهای خاص
شبکه عصبی کانولوشن، اگرچه قدرتمند هستند، اما با چالشهای متمایز در کاربرد خود، بهویژه در سناریوهایی مانند کمبود داده، برازش بیشازحد(overfitting)، و محیطهای دادهای بدون ساختار مواجه هستند. تکنیکها و الگوریتمهای آموزشی نوآورانه به این چالشها میپردازند و استحکام و کارایی CNNها را افزایش میدهند.
– رسیدگی به کمبود داده و برازش بیش از حد
یک مجموعه داده محدود میتواند منجر به برازش بیش از حد شود، که در آن مدل در یک مجموعه آموزشی خوب عمل میکند اما در دادههای دیده نشده جدید ضعیف است. افزایش دادهها در حال تبدیل شدن به یک تکنیک به طور گسترده پذیرفته شده برای غلبه بر این مشکل است.

این فرآیند شامل گسترش مصنوعی مجموعه داده آموزشی با استفاده از تبدیلهای مختلف مانند چرخش، مقیاسگذاری و انعکاس است. این کار نه تنها دادههای آموزشی را متنوع میکند، بلکه به تعمیم بهتر مدل به دادههای جدید کمک میکند. مطالعهای با عنوان “Understanding Data Augmentation for Classification: When to Warp” توسط Terrance DeVries و Graham W. Taylor اطلاعاتی را در مورد اثربخشی تکنیکهای مختلف افزایش داده در بهبود استحکام مدل ارائه میدهد. آنها عمدتاً دو روش رایج را مقایسه کردند. تاب برداشتن دادهها(data warping) و نمونهبرداری بیش از حد مصنوعی. در حالی که تاب برداشتن دادهها به طور کلی مؤثرتر بود، نتایج به طبقهبندی کننده و ماهیت دادههای شما بستگی دارد.
– CNN ها در محیطهای داده بدون ساختار
CNN ها به طور سنتی در محیطهای ساختار یافته مانند پردازش تصویر استفاده میشوند، جایی که دادهها در قالبهای شبکه مانند قرار دارند. با این حال، کاربرد آنها در محیطهای داده بدون ساختار مانند نمودارهای نامنظم یا شبکههای اجتماعی چالش برانگیز است. شبکههای کانولوشن گراف (GCN) به عنوان یک راه حل بالقوه در حال ظهور هستند. GCN ها مفهوم کانولوشن را به دادههای ساختاریافته گرافی گسترش میدهند و استخراج ویژگی را از چنین محیطهای بدون ساختاری را به طور موثر امکانپذیر میکنند. مقاله “طبقه بندی نیمه نظارت شده با شبکههای کانولوشن گراف” توسط توماس ان. کیپف و مکس ولینگ، کاربرد GCN ها را در یادگیری نیمه نظارت شده بر روی دادههای با ساختار نمودار(graph-structured) نشان میدهد.
نوآوری در الگوریتمهای آموزشی
آموزش کارآمد و موثر CNN ها برای عملکرد آنها بسیار مهم است. نوآوریهای اخیر در الگوریتمهای آموزشی بر بهینهسازی فرآیندهای یادگیری و بهبود نرخ همگرایی متمرکز است. یک مثال عادی سازی دستهای است که در مقاله “نرمال سازی دستهای: تسریع آموزش شبکه عمیق با کاهش تغییر متغیر داخلی” توسط سرگئی آیوف و کریستین سگدی شرح داده شده است. Batch Normalization ورودی تصویر را به یک لایه برای هر مینی دسته استاندارد میکند. این کار فرآیند یادگیری را تثبیت میکند و به طور قابل توجهی آموزش شبکههای عمیق را تسریع میکند. پیشرفت قابل توجه دیگر توسعه مکانیسمهای توجه در CNN ها است. مقاله «توجه تنها چیزی است که نیاز دارید» توسط واسوانی و همکاران. مدل ترانسفورماتور را معرفی کرد که به شدت بر مکانیسمهای توجه متکی است.
این مفهوم در معماریهای مختلف CNN برای بهبود توانایی آنها در تمرکز بر ویژگیهای مرتبط در دادهها اقتباس شده است. این مفهوم منجر به عملکرد بهتر، به ویژه در کارهای پیچیده مانند نوشتن شرح تصاویر(image captioning) و پاسخگویی به سؤالات بصری میشود.
شبکه عصبی کانولوشن در کاربردهای غیر بصری
CNN ها در انجام وظایف بصری عالی هستند. با این حال، کاربرد آنها در حوزههای غیر بصری مانند پردازش متن و صدا و حتی بیوانفورماتیک گسترش مییابد. برخی از معماریهای موجود در بالا از این تطبیقپذیری استفاده میکنند، مانند ویدیوهایی که تصاویر باید بر اساس نشانههای صوتی تقسیم شوند.
– پردازش متن با CNN
در پردازش متن، CNN ها به طور قابل توجهی کارآمد هستند، به ویژه در کارهایی مانند تجزیه و تحلیل احساسات، دستهبندی موضوع، و ترجمه زبانی. برخلاف روشهای سنتی پردازش متن که بر رویکردهای خطی متکی هستند، CNNها میتوانند الگوهای سلسله مراتبی را در دادههای متنی ثبت کنند. به عنوان مثال، یک مدل CNN میتواند الگوهای معنایی را در سطح کاراکتر شناسایی کند، سپس آنها را برای درک کلمات و در نهایت به دست آوردن معانی سطح جمله ترکیب کند. این پردازش سلسله مراتبی درک زبان انسان را تقلید میکند و CNN ها را در وظایف پیچیده تحلیل متن کارآمد میکند. سایر کاربردهای CNN در پردازش متن عبارتند از:
- تحلیل احساسات
- دستهبندی موضوع
- ترجمه زبان
– پردازش صدا با CNN
در پردازش صدا، CNN ها در کارهایی مانند تشخیص گفتار، طبقهبندی صدا و حتی ترکیب موسیقی نقش مهمی داشتهاند. توانایی آنها در پردازش دادههای سری زمانی و استخراج ویژگیها از صدای خام، آنها را برای تجزیه و تحلیل الگوهای پیچیده در صدا مناسب میسازد. به عنوان مثال، CNN ها میتوانند صداهای مختلف را در یک محیط تشخیص دهند که در موارد استفاده مانند دستیارهای صوتی هوشمند و سیستم های طبقهبندی صدا در نظارت شهری و حیات وحش قابل استفاده است. سایر کاربردهای CNN در پردازش صدا عبارتند از:
- تشخیص گفتار
- طبقهبندی صدا
- آهنگسازی و موسیقی
– سایر کاربردها و روندهای نوظهور
در بیوانفورماتیک، CNN ها به طور فزایندهای برای کارهایی مانند پیشبینی ساختار پروتئین و تجزیه و تحلیل دادههای ژنتیکی استفاده میشوند. ظرفیت آنها برای پردازش مجموعه دادههای بزرگ و پیچیده آنها را قادر میسازد تا الگوهایی را در توالیهای ژنتیکی کشف کنند. این کاربرد پتانسیل فراوانی در کمک به پزشکان در تشخیص بیماری و کشف دارو را دارد. مطالعات اخیر نشان دادهاند که چگونه CNNها میتوانند توالیهای ژنومی را برای شناسایی جهشها و پیشبینی حساسیت به بیماری تجزیه و تحلیل کنند و تحقیقات پزشکی شخصی و ژنومیک را متحول کنند. روندهای نوظهور شامل ادغام CNN ها با سایر تکنیکهای هوش مصنوعی مانند یادگیری تقویتی و مدلهای مولد است. این موارد زمینههای در حال گسترش قابلیتهای CNN در برنامههای غیر بصری است. بنابراین، این موضوع منجر به تولید مدلهای پیچیدهتر و دقیقتر میشود که قادر به مقابله با وظایف پیچیده در زمینههای مختلف هستند. سایر کاربردهای CNN عبارتند از:
- پیش بینی ساختار پروتئین
- تجزیه و تحلیل دادههای ژنتیکی
- شناسایی جهش
- ادغام با یادگیری تقویتی
- ترکیب با مدلهای مولد
جهتگیری و چالشهای آینده در شبکه عصبی کانولوشن
CNN ها به تکامل خود ادامه میدهند و مرزهای جدیدی را در هوش مصنوعی و یادگیری ماشین در مینوردند. با این حال، ما میتوانیم انتظار داشته باشیم که در موارد زیر شاهد پیشرفت بیشتری باشیم:
- با افزایش راندمان محاسباتی، استفاده از این تکنولوژی در دستگاههای کوچکتر در دسترستر میگردد.
- پیشرفت در پردازش دادههای سه بعدی و سریهای زمانی پیچیده.
- افزایش ادغام با سایر حوزههای هوش مصنوعی، مانند یادگیری تقویتی و یادگیری بدون نظارت.
با این حال، این پیشرفتها با مجموعهای از چالشهای جدیدی همراه است که در ادامه ذکر شده است:
- غلبه بر وابستگی شدید به مجموعه دادههای بزرگ و برچسبدار.
- پرداختن به سوگیریها برای اطمینان از عدالت در آموزش مدل.
- ساخت مدلهای CNN قابل تفسیر و توضیح بیشتر.
- بهبود انعطافپذیری CNN ها در برابر حملات خصمانه و نویز دادهها.
- این پیشرفتها و چالشها بر ماهیت پویای CNN تأکید میکند و هم پتانسیل گسترده و هم موانعی را که برای غلبه بر آنها وجود دارد، برجسته میکند.
همانطور که قبلاً دیدیم، برخی از مقالات نوآورانه قبلاً روش هایی را برای مقابله با برخی از این موانع احتمالی پیشنهاد کردهاند. شکی نیست که ما شاهد توسعه CNN های بیشتری خواهیم بود زیرا هنوز پتانسیل کامل آنها را کشف نکردهایم.