
زمان تخمینی مطالعه: 10 دقیقه
یکی از مهم ترین عملیات در بینایی کامپیوتر، بخشبندی تصویر یا Image Segmentation است. قطعهبندی تصویر فرآیند تقسیم یک تصویر به چندین قسمت یا ناحیه است که به یک کلاس تعلق دارند. این وظیفه خوشهبندی بر اساس معیارهای خاصی انجام میگردد و میتواند به عنوان مثال بر اساس رنگ یا بافت باشد. به این فرآیند طبقهبندی در سطح پیکسل نیز میگویند. به عبارت دیگر این فرآیند شامل پارتیشنبندی تصاویر (یا فریمهای ویدیویی) به بخشها یا اشیاء متعدد است.
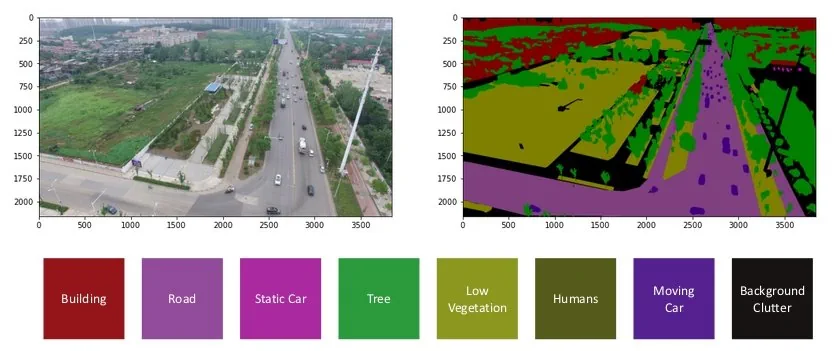
در 40 سال گذشته، روشهای تقسیمبندی مختلفی پیشنهاد شدهاند، از تقسیمبندی تصویر متلب و روشهای سنتی بینایی رایانهای تا روشهای پیشرفته یادگیری عمیق. به خصوص با ظهور شبکههای عصبی عمیق (DNN)، کاربردهای بخشبندی تصویر پیشرفت فوق العادهای داشتهاند.

تکنیکهای بخشبندی تصویر
تکنیکهای Image Segmentation مختلفی وجود دارد و هر تکنیک مزایا و معایب خاص خود را دارد که در ادامه به آنها خواهیم پرداخت.
- آستانهگذاریThresholding: آستانهگذاری یکی از سادهترین تکنیکهای بخشبندی تصویر است که در آن یک مقدار آستانه تنظیم میشود و تمام پیکسلهایی که مقادیر شدت بالاتر یا پایینتر از آستانه دارند به مناطق جداگانه اختصاص مییابند.
- رشد منطقه Region growing: در رشد منطقه، تصویر بر اساس معیارهای شباهت به چندین منطقه تقسیم میشود. این تکنیک قطعهبندی از یک نقطه شروع میشود و با افزودن پیکسلهای همسایه با ویژگیهای مشابه، منطقه را رشد میدهد.
- بخشبندی مبتنی بر لبهEdge-based segmentation: تکنیکهای بخشبندی مبتنی بر لبه بر اساس تشخیص لبهها در تصویر هستند. این لبهها مرزهای بین مناطق مختلف را نشان میدهند و با استفاده از الگوریتمهای تشخیص لبه شناسایی میشوند.
- خوشهبندی: تکنیکهای خوشهبندی پیکسلها را بر اساس معیارهای شباهت به خوشهها گروهبندی میکند. این معیارها میتواند رنگ، شدت، بافت یا هر ویژگی دیگری باشد.
- بخشبندی حوضهWatershed segmentation: تقسیمبندی حوضه بر اساس این ایده است که یک تصویر از کوچکترین بخش آن سیلآمیزی(flooding) میشود. در این تکنیک، تصویر به عنوان یک نقش برجسته توپوگرافی در نظر گرفته میشود، که در آن مقادیر شدت نشان دهنده ارتفاع زمین است.
- خطوط فعالActive contours: خطوط فعال که به عنوان مارها(snakes) نیز شناخته میشوند، منحنیهایی هستند که برای یافتن مرز یک جسم در یک تصویر تغییر شکل میدهند. این منحنیها توسط یک تابع انرژی کنترل میشوند که فاصله بین منحنی و مرز جسم را به حداقل میرساند.
- قطعهبندی مبتنی بر یادگیری عمیق: تکنیکهای یادگیری عمیق، مانند شبکههای عصبی کانولوشنال (CNN)، با ارائه راهحلهای بسیار دقیق و کارآمد، بخشبندی تصویر را متحول کردهاند. این تکنیکها از یک رویکرد سلسله مراتبی برای پردازش تصویر استفاده میکنند، که در آن لایههای متعددی از فیلترها بر روی تصویر ورودی اعمال میشود تا ویژگیهای سطح بالا استخراج شود.
- قطعهبندی مبتنی بر نمودارGraph-based segmentation: این تکنیک یک تصویر را به عنوان یک نمودار نشان میدهد و آن را بر اساس اصول تئوری گراف تقسیمبندی میکند.
- بخشبندی مبتنی بر سوپرپیکسلSuperpixel-based segmentation: این تکنیک مجموعهای از پیکسلهای تصویر مشابه را با هم گروهبندی میکند تا مناطق بزرگتر و معنادارتری به نام سوپرپیکسل تشکیل دهند.
کاربردهای بخشبندی تصویر
مشکلات Image Segmentation در طیف وسیعی از برنامههای بینایی رایانهای در دنیای واقعی، از جمله تشخیص علائم جاده، زیستشناسی، ارزیابی مصالح ساختمانی، یا امنیت و نظارت تصویری، نقش اصلی را ایفا میکنند. همچنین، خودروهای خودران و سیستمهای کمک راننده پیشرفته (ADAS) باید سطوح قابل رانندگی را شناسایی کرده یا تشخیص عابر پیاده را اعمال کنند.

علاوه بر این، بخشبندی تصویر به طور گسترده در برنامههای تصویربرداری پزشکی، مانند استخراج مرز تومور یا اندازهگیری حجم بافت به کار گرفته میشوند. در اینجا، فرصتی برای طراحی پایگاههای داده تصویر استاندارد شده بوجود آمد که میتواند برای ارزیابی بیماریها و بیماریهای همهگیر جدید (به عنوان مثال، برای کاربردهای بینایی هوش مصنوعی در کنترل ویروس کرونا) استفاده شود.
بخشبندی تصویر مبتنی بر یادگیری عمیق با موفقیت در قطعهبندی تصاویر ماهوارهای در زمینه سنجش از دور، از جمله تکنیکهای برنامهریزی شهری یا کشاورزی دقیق، به کار گرفته شده است. همچنین، تصاویر جمعآوریشده توسط پهپادها با استفاده از تکنیکهای مبتنی بر یادگیری عمیق تقسیمبندی شدهاند و فرصتی را برای رسیدگی به مشکلات مهم زیست محیطی مرتبط با تغییرات آب و هوایی ارائه میدهند.
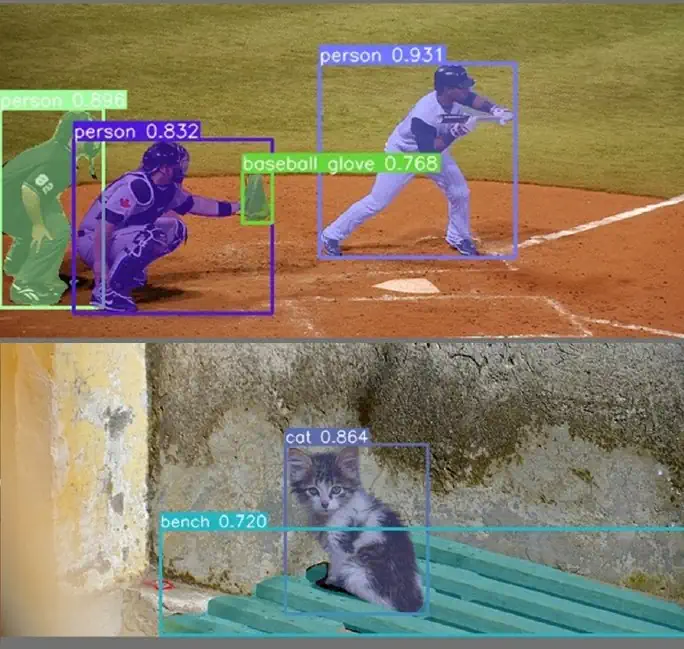
بخشبندی معنایی در مقابل بخشبندی نمونه
قطعهبندی تصویر را میتوان به عنوان یک مسئله طبقهبندی پیکسلها با برچسبهای معنایی (بخشبندی معنایی) یا پارتیشنبندی اشیاء مجزا (بخشبندی نمونه) فرمولبندی کرد. بخشبندی معنایی برچسبگذاری کلاس در سطح پیکسل را با مجموعهای از دستهبندی اشیاء (به عنوان مثال، مردم، درختان، آسمان، اتومبیلها) برای همه پیکسلهای تصویر انجام میدهد. معمولاً این کار دشوارتر از طبقهبندی تصویر است که یک برچسب واحد را برای کل تصویر یا فریم پیش بینی میکند. بخشبندی نمونه، دامنه تقسیمبندی معنایی را با شناسایی و ترسیم تمام اشیاء مورد علاقه در یک تصویر، بیشتر میکند.
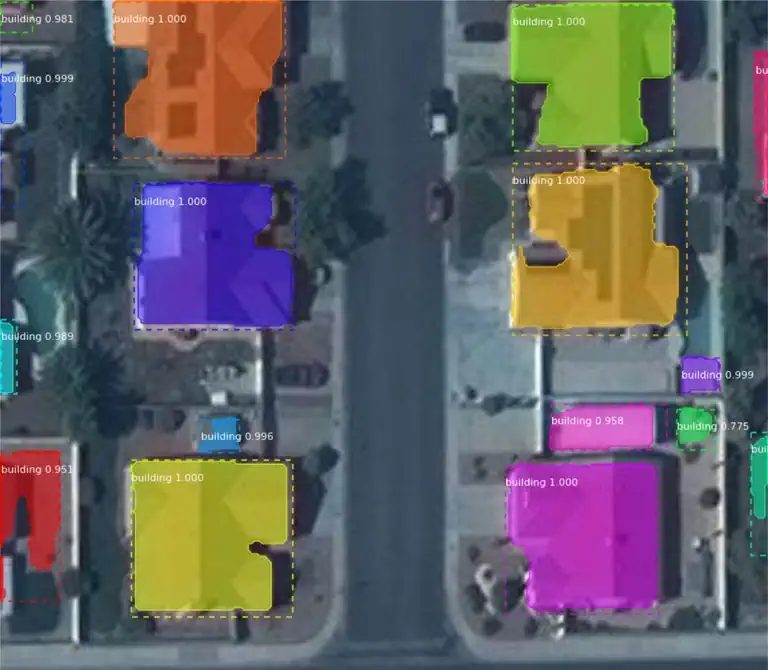
بخشبندی تصویر و یادگیری عمیق
چندین نمونه مختلف الگوریتم Image Segmentation توسعه داده شده است. روشهای قبلی عبارتند از آستانهگذاری، بستهبندی مبتنی بر هیستوگرام، رشد منطقه، خوشهبندی k-means یا بخش بندی حوزه. با این حال، الگوریتمهای پیشرفتهتر مبتنی بر خطوط فعال، برشهای نمودار، میدانهای تصادفی شرطی و مارکوف و روشهای مبتنی بر پراکندگی هستند. در چند سال گذشته، مدلهای یادگیری عمیق بخش جدیدی از مدلهای قطعهبندی تصویر را با بهبود عملکرد قابلتوجهی معرفی کردهاند. مدلهای بخشبندی تصویر مبتنی بر یادگیری عمیق اغلب بهترین نرخهای دقت را در معیارهای رایج به دست میآورند که منجر به تغییر پارادایم در زمینه میشود.

محبوبترین مجموعه دادههای بخشبندی تصویر
با توجه به موفقیت مدلهای یادگیری عمیق در طیف وسیعی از کاربردهای بینایی، تحقیقات زیادی با هدف توسعه رویکردهای قطعهبندی تصویر با استفاده از یادگیری عمیق انجام شده است. در حال حاضر، مجموعه دادههای کلی زیادی در رابطه با قطعهبندی تصویر وجود دارد. محبوبترین مجموعه دادههای بخشبندی تصویر عبارتند از:
- PASCAL VOC: مجموعه داده PASCAL VOC یکی از محبوبترین مجموعهدادهها درحوزه بینایی کامپیوتر است که تصاویر مشروح برای 5 وظیفه را در دسترس قرار میدهد: طبقهبندی، بخشبندی، تشخیص، شناسایی عمل و طرحبندی افراد. تعداد زیادی از الگوریتمهای بخشبندی محبوب بر روی این مجموعه داده ارزیابی شده است. برای کارهای بخشبندی، PASCAL VOS از 21 کلاس برچسب اشیا پشتیبانی میکند که شامل وسایل نقلیه، خانواده، حیوانات، هواپیما، دوچرخه، قایق، اتوبوس، ماشین، موتور سیکلت، قطار، بطری، صندلی، میز ناهار خوری، گیاه گلدانی، مبل، تلویزیون/مانیتور، پرنده، گربه، گاو، سگ، اسب، گوسفند و شخص است. پیکسلها در تصویر اگر به هیچ یک از این کلاسها تعلق نداشته باشند به عنوان “پس زمینه” برچسب گذاری میشوند. دادههای آموزشی/تأیید اعتبار PASCAL VOC دارای 11.530 تصویر است که شامل 27.450 ROI شی حاشیه نگاری شده و 6.929 بخشبندی است.
- MS COCO: پایگاه داده Microsoft Common Objects in Context (MS COCO) یک مجموعه داده شناسایی، بخشبندی و زیرنویس اشیاء در مقیاس بزرگ است. COCO شامل تصاویری از صحنههای پیچیده روزمره است که شامل اشیاء مشترک در زمینه طبیعی آنها میشود. بنابراین، COCO بر اساس مجموع 2.5 میلیون نمونه بخشبندی شده برچسبگذاری شده در 328 هزار تصویر است که حاوی عکسهایی از 91 نوع شی است که توسط یک فرد 4 ساله به راحتی قابل تشخیص است.
- Cityscapes: پایگاه داده در مقیاس بزرگ بر درک معنایی صحنههای خیابان شهری متمرکز است. Cityscapes شامل مجموعهای متنوع از سکانسهای ویدیویی استریو ضبط شده در صحنههای خیابانی از 50 شهر، 5000 تصویر کاملاً حاشیهنویسی شده و مجموعهای از 20000 فریم با حاشیهنویسی ضعیف است. همچنین زمان جمع آوری آن شامل چندین ماه است که فصول بهار، تابستان و پاییز را در بر میگیرد. مناظر شهری شامل حاشیهنویسیهای پیکسلی معنایی و متراکم از 30 کلاس است که در 8 دسته (سطوح صاف، انسان، وسایل نقلیه، سازهها، اشیاء، طبیعت، آسمان و فضای خالی) گروهبندی شدهاند. مجموعه داده به ویژه برای برنامههای کاربردی رانندگی خودران از اهمیت بالایی برخوردار است.
- ADE20K: پایگاه داده ADE20K یک پلت فرم آموزشی و ارزیابی استاندارد برای الگوریتمهای تجزیه صحنه ارائه میدهد. مجموعه داده ADE20K شامل بیش از 20000 تصویر صحنه محور است که با اشیاء و قطعات شیء حاشیهنویسی شدهاند و 150 دسته معنایی را ارائه میدهد. برخلاف سایر مجموعههای داده، ADE20K شامل یک ماسک بخشبندی شی و یک ماسک بخشبندی قطعات است. 20210 تصویر رنگی در مجموعه آموزشی، 2000 تصویر در مجموعه اعتبارسنجی و 3000 تصویر در مجموعه تست وجود دارد.
- YouTube-Objects: مجموعه داده YouTube-Objects از ویدیوهایی تشکیل شده است که با جستجوی نام 10 کلاس شی از YouTube جمعآوری شدهاند. به طور خاص، شامل اشیایی از 10 کلاس PASCAL VOC هواپیما، پرنده، قایق، ماشین، گربه، گاو، سگ، اسب، موتور سیکلت و قطار است. مجموعه داده اصلی برای تشخیص اشیاء با حاشیهنویسی ضعیف توسعه داده شد و حاوی حاشیهنویسی پیکسلی نبود. بنابراین، مجموعه دادههای بخشبندی اشیاء ویدیویی YouTube (YouTube-VOS) با حاشیهنویسی کامل منتشر شد که شامل ۴،۴۵۳ کلیپ ویدیویی یوتیوب و ۹۴ دسته شیء است.
- KITTI: مجموعه داده KITTI یکی از محبوبترین مجموعه دادهها برای روباتیک متحرک و رانندگی خودکار است. این مجموعه داده شامل ساعتها ویدیو از سناریوهای ترافیکی است که با رانندگی در شهر متوسط کارلسروهه (در بزرگراهها و مناطق روستایی) ضبط شدهاند. به طور متوسط در هر تصویر تا 15 خودرو و 30 عابر پیاده قابل مشاهده است. وظایف اصلی این مجموعه داده عبارتند از: تشخیص جاده، بازسازی استریو، جریان نوری، کیلومتر شماری بصری، تشخیص اشیاء سه بعدی و ردیابی سه بعدی است. مجموعه داده اصلی حاوی حقیقت پایه برای تقسیم بندی معنایی نیست، اما محققان به صورت دستی بخشهایی از مجموعه داده را حاشیهنویسی کردهاند.