زمان تخمینی مطالعه: 8 دقیقه
OCR (تشخیص کاراکتر نوری) یا کاراکتر خوان نوری فرآیند تبدیل متن چاپ شده یا دستنویس به فرمت دیجیتال با پردازش تصویر را توصیف میکند. تشخیص کاراکتر نوری حوزه قابل توجهی از تحقیقات در هوش مصنوعی، تشخیص الگو و بینایی کامپیوتری است. OCR همچنین یکی از اولین زمینههای تحقیقات فناوری هوش مصنوعی بود و به عنوان یک فناوری بالغ ظهور کرده است. OCR در سال 1913 آغاز شد، زمانی که دکتر ادموند فورنیر دالبه، اپتوفون را برای اسکن و تبدیل متن به صدا برای افراد کم بینا اختراع کرد. از آن زمان، فناوری OCR مراحل توسعه متعددی را تجربه کرده است. در دهه 1990، این فناوری با دیجیتالی کردن روزنامههای تاریخی برجسته شد. علاوه بر این، ظهور گوشیهای هوشمند و اسناد الکترونیکی منجر به پیشرفتهای بیشتر در فناوری OCR شد. الگوریتم MaskOCR که مبتنی بر Vision Transformers (ViT) است و در ژوئن 2022 منتشر شد، بهترین الگوریتم OCR است و نتایج بسیار قابل توجهی را در مجموعه دادههای بنچمارک برای تصاویر متنی چینی و انگلیسی به دست آورده است.
تشخیص کاراکتر نوری (OCR) چیست؟
OCR مخفف Optical Character Recognition است و به یک فناوری نرم افزاری اشاره دارد که به صورت الکترونیکی متن (نوشته یا چاپ شده) را در داخل یک فایل تصویر یا سند فیزیکی، مانند یک سند اسکن شده شناسایی میکند و آن را به یک فرم متن قابل خواندن توسط ماشین تبدیل میکند تا برای پردازش دادهها استفاده شود. این تکنولوژی همچنین به عنوان تشخیص متن نیز شناخته میشود. به طور خلاصه، نرم افزار تشخیص کاراکتر نوری به تبدیل تصاویر یا اسناد فیزیکی به فرمت قابل جستجو کمک میکند. از نمونههای OCR میتوان به ابزارهای استخراج متن، مبدلهای PDF به txt و عملکرد جستجوی تصویر Google اشاره کرد.

تشخیص متن صحنه (STR) چیست؟
در بینایی کامپیوتری، ماشینها میتوانند متن را در صحنههای طبیعی ابتدا با شناسایی نواحی متن، برشدادن آن نواحی، و متعاقباً تشخیص متن در آن مناطق بخوانند. وظیفه بینایی تشخیص متن از مناطق برش خورده، تشخیص متن صحنه (STR) نامیده میشود. STR خواندن علائم جادهای، بیلبوردها، آرمها و اشیاء چاپی مانند متن روی پیراهن، صورتحسابهای کاغذی و غیره را ممکن میسازد. کاربردهای STR شامل موارد استفاده عملی مانند خودروهای خودران، واقعیت افزوده، تجزیه و تحلیل خردهفروشی، آموزش، دستگاههایی برای افراد کم بینا و دیگران است.
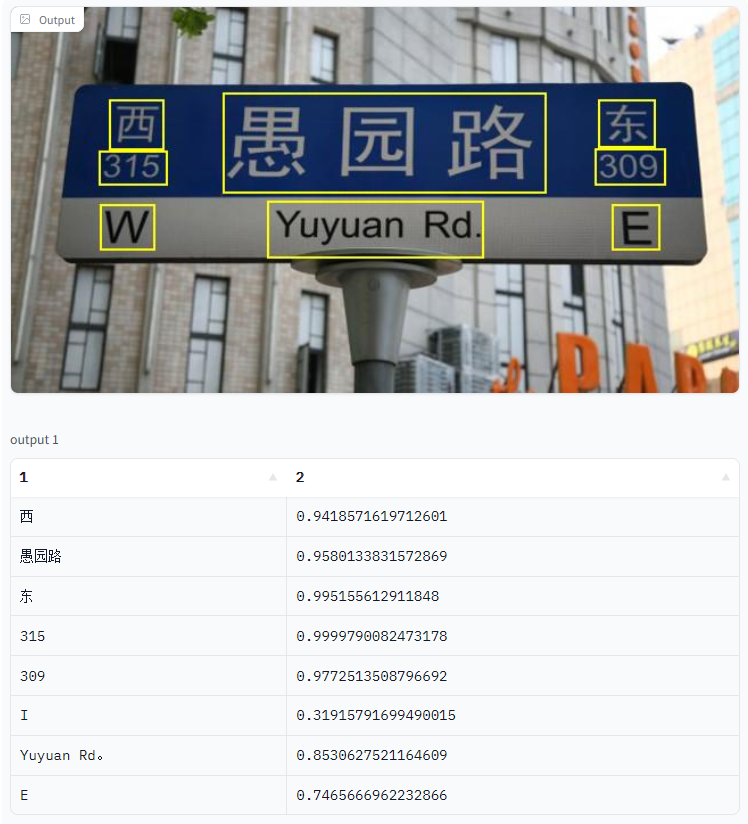
تفاوت بین OCR و STR چیست؟
با مقایسه OCR و STR، تشخیص کاراکتر نوری (OCR) را میتوان در جایی که ویژگیهای متن در یک فرم ورودی یکنواخت ارائه میشود، اعمال کرد. درحالی که STR قادر به خواندن متن با سبکهای مختلف فونت، اشکال متن، روشنایی، جهتگیری، انسداد (متن تا حدی پنهان) و شرایط ناسازگار دوربین است. به طور کلی، تشخیص متن صحنه(STR) برای خواندن متن با الگوریتمهای هوش مصنوعی در سناریوهای دنیای واقعی که شامل محیطهای بسیار چالش برانگیز و طبیعی با تصاویر ورودی نویز، تار یا تحریف شده است، ابزاری ایده آل است.
تشخیص کاراکتر نوری چگونه کار میکند؟
مفهوم OCR ساده است. با این حال، اجرای آن به دلیل عوامل متعددی مانند انواع فونتها یا روشهای مورد استفاده برای شکلگیری حروف میتواند بسیار چالش برانگیز باشد. به عنوان مثال، زمانی که نمونههای دستخط غیر دیجیتالی به جای نوشتن تایپ شده به عنوان ورودی استفاده میشود، اجرای OCR میتواند به طور تصاعدی پیچیدهتر شود. کل فرآیند OCR شامل یک سری مراحل است که عمدتاً شامل سه هدف است: پیش پردازش تصویر، تشخیص کاراکتر، و پس پردازش خروجی خاص تولید شده. وظایف پایین دستی OCR شامل پردازش زبان طبیعی (NLP) برای نه تنها خواندن، بلکه تجزیه و تحلیل و درک معنای متن و گفتار است.
فرآیند OCR در بینایی کامپیوتری
در ادامه نحوه عملکرد تشخیص کاراکتر نوری را نشان خواهیم داد و مراحل اصلی فناوریهای OCR سنتی را توضیح خواهیم داد.
- اسکن سند: این مرحله اصلی OCR است که برای اسکن سند به یک اسکنر متصل میشود. اسکن سند تعداد متغیرهایی را که باید در هنگام ایجاد نرم افزار OCR در نظر گرفته شود کاهش میدهد زیرا ورودیها را استاندارد میکند. همچنین، این مرحله به طور خاص کارایی کل فرآیند را با اطمینان از تراز و اندازه کامل سند خاص افزایش میدهد. این مرحله اولیه همچنین میتواند شامل تشخیص شی، برای تمرکز وظایف پردازش بینایی بعدی بر روی مناطق خاص تصویر باشد.
- تصحیح تصویر: در این مرحله، نرم افزار تشخیص کاراکتر نوری عناصر سند را که باید گرفته شوند، بهبود میبخشد. هر گونه نقصی مانند ذرات گرد و غبار از بین میرود و لبهها و همچنین پیکسلها صاف میشوند تا متنی ساده و واضح داشته باشند. این مرحله گرفتن دادهها را برای برنامه آسانتر میکند در حالی که میتواند کلمات وارد شده را بدون لکه یا مناطق تاریک نامنظم به وضوح ببیند. چنین وظایف پردازش تصویر در همه انواع خطوط لوله بینایی، برای وضوح یا روشن کردن خودکار تصاویر ضروری است.
- باینری کردن: سند تصویر تصحیح شده سپس به یک تصویر سند دو سطحی تبدیل میشود که فقط حاوی رنگهای سیاه و سفید است، جایی که مناطق سیاه یا تاریک به عنوان کاراکتر مشخص میشوند. در همان زمان، مناطق سفید یا روشن به عنوان پس زمینه شناسایی میشوند. هدف این مرحله اعمال تقسیمبندی به سند است تا متن پیش زمینه را از پس زمینه به راحتی متمایز کند، که امکان تشخیص بهینه کاراکترها را فراهم میکند.
- تشخیص کاراکترها: در این مرحله، نواحی سیاه بیشتر برای شناسایی حروف یا ارقام پردازش میشوند. معمولاً یک OCR در یک زمان روی یک کاراکتر یا بلوک متن تمرکز میکند. تشخیص کاراکترها با استفاده از یکی از دو نوع الگوریتم زیر انجام میشود:
- تشخیص الگو: الگوریتم تشخیص الگو شامل درج متن با فونتها و فرمتهای مختلف در نرم افزار OCR است. سپس نرم افزار اصلاح شده برای مقایسه و تشخیص کاراکترهای سند اسکن شده استفاده میشود.
- تشخیص ویژگی: از طریق الگوریتم تشخیص ویژگی، نرم افزار OCR قوانینی را با در نظر گرفتن ویژگیهای یک حرف یا عدد خاص برای شناسایی کاراکترهای سند اسکن شده اعمال میکند. نمونههایی از ویژگیها عبارتند از تعداد خطوط زاویهدار، خطوط متقاطع، یا منحنیهای مورد استفاده برای مقایسه و شناسایی کاراکترها. چنین تکنیکهای تشخیص متن اساس اکثر روشهای یادگیری عمیق مبتنی بر OCR هستند.
نرم افزار ساده OCR پیکسلهای هر حرف اسکن شده را با پایگاه داده موجود مقایسه میکند تا نزدیکترین مورد را شناسایی کند. با این حال، اشکال پیچیده OCR، هر کاراکتر را به اجزای آن، مانند منحنیها و گوشهها، برای مقایسه و تطبیق ویژگیهای فیزیکی با حروف مربوطه تقسیم میکند.
- بررسی صحت: پس از تشخیص موفقیت آمیز کاراکترها، نتایج با استفاده از فرهنگ لغتهای داخلی نرم افزار OCR برای اطمینان از دقت، ارجاع متقابل میشوند. اندازهگیری دقت OCR با گرفتن خروجی تجزیه و تحلیل انجام شده توسط OCR و مقایسه آن با محتوای نسخه اصلی انجام میشود. دو روش معمولی برای تجزیه و تحلیل دقت نرم افزار OCR وجود دارد:
- دقت در سطح کاراکتر: شمارش تعداد کاراکترهایی که به درستی شناسایی شدند.
- دقت در سطح کلمه: شمارش تعداد کلمات به درستی تشخیص داده شده است.
در بیشتر موارد، دقت 98-99% میزان دقت قابل قبولی است که در سطح صفحه (نه سطح الگوریتم) اندازهگیری میشود. این بدان معناست که در یک صفحه با حدود 1000 کاراکتر، 980-990 کاراکتر باید به طور دقیق توسط نرم افزار OCR شناسایی شود.
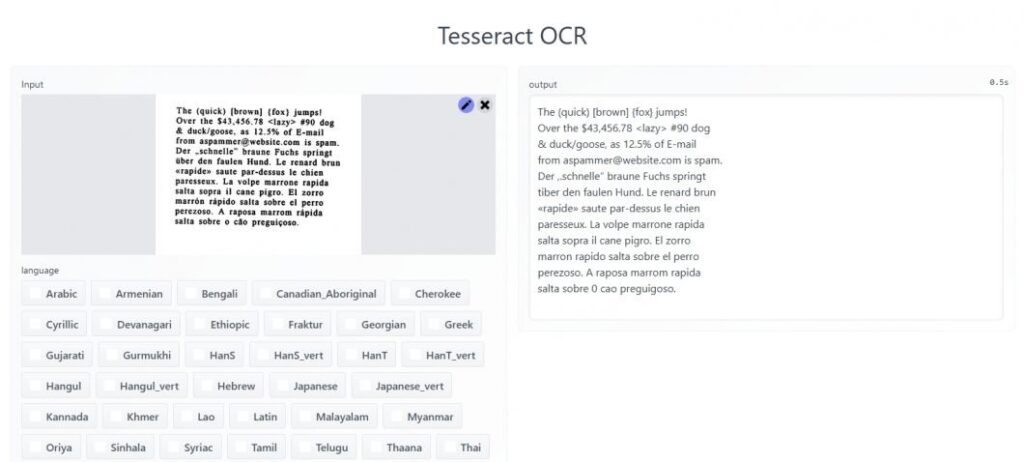
تشخیص کاراکتر نوری Tesseract
Tesseract یک موتور تشخیص کاراکتر است که میتواند متن اسکن شده را بخواند و آن را به متن دیجیتال تبدیل کند. این نرم افزار منبع باز است که تحت مجوز Apache 2.0 منتشر شده است. Tesseract برای سیستم عاملهای مختلف از جمله ویندوز، لینوکس و Mac OS X در دسترس است. از این رو، Tesseract یک ابزار محبوب برای تشخیص متن در تصاویر، مانند اسناد اسکن شده و عکسهای دیجیتال است. Tesseract دقیق و کارآمد است و میتواند زبانهای مختلفی را پشتیبانی کند. برای تشخیص متن در تصاویر با Tesseract، تصاویر حاوی متن را وارد میکنید. Tesseract میتواند انواع فرمتهای تصویر از جمله JPG، PNG و TIFF را بخواند.