این مقاله مقدمهای بر جمعآوری داده برای بینایی کامپیوتری و آموزش آن توسط مدلهای هوش مصنوعی ارائه شده است. آماده سازی دادهها برای یادگیری ماشین (ML) یک گام اساسی به سمت آموزش یک مدل ML با کارایی بالا است که میتواند توسط رایانهها برای تجزیه و تحلیل دادههای ویدیویی یا تصویری استفاده شود. جمعآوری داده برای بینایی کامپیوتری دارای اهمیت فوق العادهای در حوزه هوش مصنوعی بوده و بدون آن هیچ کدام از الگوریتمهای مطرح شده جدید قابلیت تست و بررسی را نخواهند داشت.
جمعآوری دادهها برای آموزش مدلهای هوش مصنوعی
مدلهای هوش مصنوعی برنامههای نرمافزاری هستند که بر روی مجموعهای از دادهها برای انجام وظایف تصمیمگیری خاص آموزش دیدهاند. به زبان ساده، این مدلها برای تکرار تفکر و فرآیند تصمیمگیری متخصصان انسانی ایجاد شدهاند. روشهای هوش مصنوعی مشابه انسانها به مجموعه دادههایی نیاز دارند که از (واقعیت زمینه) یاد بگیرند تا بینشها را روی دادههای جدید اعمال کنند. فرآیند جمعآوری داده برای بینایی کامپیوتری برای توسعه یک مدل کارآمد ML بسیار مهم است. کیفیت و کمیت مجموعه داده شما مستقیماً بر فرآیند تصمیمگیری مدل هوش مصنوعی تأثیر میگذارد. و این دو عامل استحکام، دقت و عملکرد الگوریتمهای هوش مصنوعی را تعیین میکنند. در نتیجه، جمعآوری و ساختاردهی دادهها اغلب زمانبرتر از آموزش مدل بر روی دادهها است.
جمعآوری دادهها قبل از فرآیند حاشیهنویسی تصویر اتفاق میافتد که فرآیند ارائه دستی اطلاعات در مورد حقیقت پایه در مورد دادهها است. به عبارت ساده، حاشیه نویسی تصویر، فرآیند نشان دادن بصری مکان و نوع اشیایی است که مدل هوش مصنوعی باید تشخیص دهد. به عنوان مثال، برای آموزش یک مدل یادگیری عمیق برای تشخیص گربهها، نیازمند حاشیه نویسی تصویر توسط انسان است تا جعبههایی را در اطراف همه گربههای موجود در هر تصویر یا فریم ویدیو بکشد. در این مورد، جعبههای مرزی به برچسبی به نام «گربه» مرتبط میشوند. مدل آموزش دیده قادر خواهد بود حضور گربهها را در تصاویر جدید تشخیص دهد.
مفهوم جمعآوری داده برای یادگیری ماشین چیست؟
جمعآوری داده برای بینایی کامپیوتری فرآیند گردآوری دادههای مرتبط و ترتیب دادن آنها برای ایجاد مجموعههای داده برای یادگیری ماشین است. نوع دادهها (توالیهای ویدیویی، قابها، عکسها، الگوها و غیره) به مشکلی بستگی دارد که مدل هوش مصنوعی قصد دارد آن را حل کند. در بینایی کامپیوتر، رباتیک و تجزیه و تحلیل ویدیویی، مدلهای هوش مصنوعی بر روی مجموعه دادههای تصویری با هدف پیشبینیهای مربوط به طبقهبندی تصویر، تشخیص اشیا،بخشبندی تصویر و موارد دیگر آموزش داده میشوند. بنابراین، مجموعه دادههای تصویری یا ویدیویی باید حاوی اطلاعات معناداری باشد که بتوان از آن برای آموزش مدل برای شناخت الگوهای مختلف و ارائه توصیههایی بر اساس آن استفاده کرد. بنابراین، موقعیتهای مشخصه باید به تصویر کشیده شوند تا حقیقتی برای مدل ML فراهم شود تا از آن درس بگیرد. به عنوان مثال، در اتوماسیون صنعتی، دادههای تصویری باید جمعآوری شوند که حاوی عیوب قطعه خاصی باشند. بنابراین یک دوربین نیاز به جمعآوری فیلم از خطوط مونتاژ برای ارائه تصاویر ویدیویی یا عکس دارد که میتواند برای ایجاد یک مجموعه داده استفاده شود.
تشخیص قطعات معیوب با استفاده از یادگیری عمیق.
نحوه ایجاد یک مجموعه داده تصویری برای یادگیری ماشین
ایجاد یک مجموعه داده یادگیری ماشینی مناسب، یک فرآیند پیچیده و پر زحمت است. برای به دست آوردن دادهها باید از یک رویکرد ساختاریافته پیروی کنید که بتوان از آن برای تشکیل یک مجموعه داده با کیفیت بالا استفاده کرد. اولین گام در جمعآوری دادهبرای بینایی ماشین، شناسایی منابع مختلف دادهای است که برای آموزش مدل خاص استفاده میکنید. منابع مختلفی برای جمعآوری دادههای تصویری یا ویدیویی برای کارهای مربوط به بینایی کامپیوتری وجود دارد.
– استفاده از مجموعه دادههای تصویر عمومی
ساده ترین راه این است که یک مجموعه داده یادگیری ماشین عمومی را انتخاب کنید. این مجموعه دادهها عموماً بهصورت آنلاین در دسترس هستند، منبع باز هستند و برای استفاده، اشتراکگذاری و تغییر توسط هر کسی رایگان هستند. با این حال، مطمئن شوید که مجوز مجموعه داده را بررسی کنید. اگر برای پروژههای ML تجاری استفاده شود، بسیاری از مجموعههای داده عمومی نیاز به اشتراک یا مجوز پولی دارند. به طور خاص، مجوزهای کپیلفت در صورت استفاده در پروژههای تجاری ممکن است خطراتی را به همراه داشته باشد، زیرا مستلزم آن است که هر اثر مشتق شده (مدل شما یا کل برنامه هوش مصنوعی) تحت همان مجوز کپیلفت در دسترس باشد.
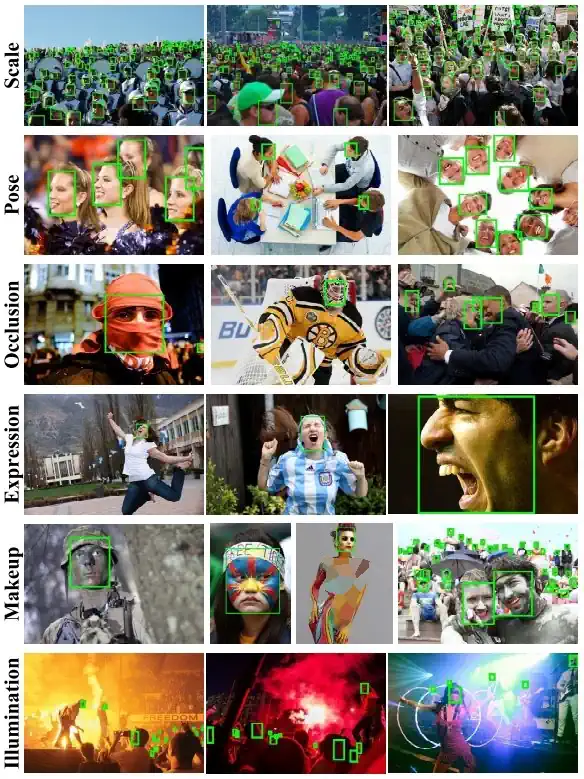
مجموعه دادههای عمومی شامل مجموعهای از دادهها برای یادگیری ماشینی است، برخی از آنها حاوی میلیونها نقطه داده و مقدار زیادی حاشیهنویسی هستند که میتوانند برای آموزش یا تنظیم دقیق مدلهای هوش مصنوعی دوباره استفاده شوند. در مقایسه با ایجاد یک مجموعه داده سفارشی از طریق جمعآوری دادهها یا تصاویر ویدیویی، استفاده از مجموعه داده عمومی بسیار سریعتر و ارزانتر است. استفاده از یک مجموعه داده کاملاً آماده در صورتی مطلوب است که وظیفه تشخیص شامل اشیاء مشترک (افراد، چهرهها) یا موقعیتها باشد و خیلی خاص نباشد. برخی از مجموعههای داده برای وظایف بینایی کامپیوتری خاص مانند تشخیص اشیاء، تشخیص چهره یا تخمین موقعیت(Position) ایجاد میشوند. از این رو، آنها ممکن است برای آموزش مدلهای هوش مصنوعی خود برای حل یک مشکل دیگر نامناسب باشند. در این مورد، ایجاد یک مجموعه داده سفارشی مورد نیاز است.
نمونهای از مجموعه داده عمومی WIDER FACE برای تشخیص چهره.
– ایجاد یک مجموعه داده سفارشی
مجموعههای آموزشی سفارشی برای یادگیری ماشین را میتوان با جمعآوری دادهها با استفاده از ابزارهای نرمافزار خراشدهنده وب(web scraping)، دوربینها و سایر دستگاههای دارای حسگر (تلفن همراه، دوربینهای فیلمبرداری مدار بسته، وبکمها و غیره) ایجاد کرد. ارائه دهندگان خدمات مجموعه داده شخص ثالث میتوانند در جمعآوری دادهها برای وظایف یادگیری ماشینی کمک کنند. اگر منابع یا ابزار نرم افزاری برای ایجاد یک مجموعه داده با کیفیت ندارید، این انتخاب خوبی است. استفاده از دستگاههای لبهای یکسان برای جمعآوری دادههای آموزشی ML و انجام وظایف استنتاج روند جدیدی در هوش مصنوعی Edge است که امکان یادگیری ماشینی با کارایی بالا با مجموعههای داده کوچک را فراهم میکند. صرف نظر از اینکه از کدام منبع جمعآوری داده استفاده میکنید، مهم است که دادهها را با اهداف و ویژگیهای خاص یادگیری ماشین یا کار بینایی کامپیوتری هماهنگ کنید. علاوه بر این، باید دادهها را حاشیهنویسی کنید و نقاط داده را به طور مناسب برچسب گذاری کنید تا به خوبی با نوع الگوریتم هوش مصنوعی که قصد استفاده از آن را دارید مطابقت داشته باشد.
مجموعه دادههای تصویر
بیشتر مدلهای مربوط به بینایی کامپیوتری بر روی مجموعههای دادهای متشکل از صدها (یا حتی هزاران) تصویر آموزش داده میشوند. یک مجموعه داده خوب برای اطمینان از اینکه مدل هوش مصنوعی شما میتواند نتایج را با دقت بالا طبقهبندی یا پیشبینی کند ضروری است. با این حال، روشهای جدید بسیار کارآمدتر هستند و امکان دستیابی به همان دقت/عملکرد را با مجموعه دادههای بسیار کوچکتر فراهم میکنند. چند ویژگی کلیدی وجود دارد که میتواند به شما در شناسایی یک مجموعه داده تصویری خوب برای بهبود دقت الگوریتم بینایی کامپیوتر کمک کند.
اولاً، تصاویر موجود در دادههای شما باید کیفیت بالایی داشته باشند. به عبارت دیگر، تصویر باید به اندازه کافی دقیق باشد تا مدل هوش مصنوعی بتواند شی مورد نظر را شناسایی و مکانیابی کند. در بیشتر موارد، الگوریتمهای هوش مصنوعی هنوز به دقت در سطح انسان در وظایف بینایی رایانه دست پیدا نمیکنند. بنابراین، اگر در نگاه اول در شناسایی شیء در یک تصویر مشکل دارید، نمیتوانید انتظار داشته باشید که مدل یادگیری ماشین شما نتایج دقیقی ارائه دهد.
ثانیا، دادههای تصویری جمعآوری شده باید تنوع داشته باشند. هرچه تنوع در مجموعه داده آموزشی بیشتر باشد، استحکام الگوریتم هوش مصنوعی و عملکرد آن در تنظیمات مختلف بهتر است. اگر مجموعهای سالم از اشیاء، سناریوها یا حتی گروهها نداشته باشید، مدل بینایی کامپیوتری شما مطمئناً برای حفظ ثبات در پیشبینیهای خود مشکل دارد.
سوم، کمیت یک عامل بسیار مهم است. به طور کلی، مجموعه دادههای شما باید از تعداد زیادی عکس تشکیل شده باشد و هر چه بیشتر باشد به همان نسبت بهتر خواهد بود. در حالت کلی آموزش مدلها بر روی تعداد زیادی داده با برچسب دقیق، شانس آنها را برای پیشبینی دقیق را به حداکثر میرساند. نه تنها تعداد تصاویر، بلکه چگالی اشیاء هدف درون تصاویر نیز برای یک مجموعه داده خوب بسیار مهم است.
– بهترین منابع عمومی برای جمعآوری دادههای تصویری
ImageNet: مجموعه داده ImageNet یکی از محبوبترین پایگاه دادههای تصویر برای برنامههای بینایی کامپیوتر است. این مجموعه داده بیش از 14 میلیون تصویر حاشیهنویسی شده را ارائه میدهد که در 20000 دسته تقسیم شدهاند و یک پایگاه داده باز است که برای استفاده غیرتجاری برای محققان رایگان است.
MS Coco: پایگاه داده MS Coco که مخفف عبارت Common Objects in Context است، مجموعه داده تصویری در مقیاس بزرگ است که توسط مایکروسافت منتشر شده است. این مجموعه گستردهای دادههای تصویر حاشیهنویسی دارد که به طور خاص برای برنامه های کاربردی شناسایی تصویر، بخشبندی، و زیرنویس مفید است.
تصاویر باز گوگل Google’s Open Images: مجموعه دادههای تصاویر باز (OID) یک پروژه منبع باز است که توسط گوگل منتشر شده است. مجموعه داده رایگان مجموعهای از بیش از 9 میلیون تصویر را ارائه میدهد که با حاشیهنویسی غنی در دسترس هستند (به طور متوسط 8.4 شی در هر تصویر). این پایگاه داده نمونههایی را برای وظایف یادگیری ماشین و بینایی کامپیوتر فراهم میکند. OID تحت مجوز CC-by 4.0 ارائه شده است که امکان استفاده تجاری را فراهم میکند (حق نشر رایگان).
CIFAR-10: پایگاه داده CIFAR-10 یکی از پرکاربردترین مجموعه دادهها در بینایی کامپیوتر است. این مجموعه داده به 10 کلاس تقسیم میشود که هر کدام دارای 6000 تصویر با وضوح پایین، در مجموع 50000 تصویر آموزشی و 10000 تصویر آزمایشی است. مجموعه داده CIFAR-10 در درجه اول برای اهداف تحقیقاتی استفاده میشود.
مجموعه دادههای ویدیویی
در حالی که مدلهای بینایی کامپیوتری عمدتاً بر روی مجموعه دادههای تصویری آموزش داده میشوند، ممکن است در شرایط خاص نتایج رضایتبخشی ارائه نکنند. برای مثال، زمانی که یک مدل بینایی کامپیوتری برای کارهایی مانند طبقهبندی ویدیو، تشخیص حرکت، تشخیص فعالیتهای انسانی، تشخیص ناهنجاری یا ردیابی اشیاء ویدیویی میسازید، ممکن است به نتایج مناسبی نرسید. به طور کلی، ویدیوها فقط مجموعهای از تصاویر هستند که به ترتیب خاصی مرتب شدهاند. از این رو، جمعآوری دادههای ویدیویی ML شامل جمعآوری و حاشیهنویسی تصاویر (فریمها) نیز میشود. بنابراین، مدلهایی که بر روی دادههای ویدیویی آموزش داده شدهاند، کاملاً مشابه مدلهایی هستند که بر روی مجموعه دادههای تصویری آموزش دیدهاند. فرآیند جمع آوری داده های ویدیویی اساساً با شناسایی بهترین منابع آغاز میشود. آموزش مدل بینایی کامپیوتری خود بر روی مجموعه دادههای ویدیویی با کیفیت بالا برای افزایش دقت پیشبینیها بسیار مهم است.
ابزارهای جمعآوری دادههای ویدیویی، یادگیری ماشینی و حاشیه نویسی
ابزارهای منبع باز محبوب برای جمعآوری داده برای بینایی کامپیوتری جهت ضبط فیلمهای ویدیویی شامل OBS Studio یا VirtualDub هستند. با این حال، ذخیره فریمهای خام بدون افت کیفیت به طرز شگفتآوری چالش برانگیز است زیرا نمونهبرداری پایین (کاهش نرخ بیت)، تغییر مقیاس، تبدیل میتواند کیفیت تصویر را تغییر دهد و در نهایت منجر به عملکرد ضعیف الگوریتم شود. هنگامی که از یک پلتفرم بینایی کامپیوتری انتها به انتها استفاده میکنید، میتوانید دادهها را در یک مکان جمعآوری، ذخیره و حاشیه نویسی کنید. این احتمالاً بهترین نتایج را ارائه میکند زیرا میتوانید دادههای بسیار مرتبط را از دستگاههایی که مدل هوش مصنوعی آموزشدیده بعداً در آنها مستقر میشود جمعآوری کنید. این بدان معنی است که برای آموزش مدل ML خود و دستیابی به کارایی بهتر و عملکرد یادگیری ماشینی راه حلهای بینایی کامپیوتری سفارشی، به یک مجموعه داده تصویری کوچک نیاز دارید.
برای حاشیهنویسی دادههای تصویری که جمعآوری کردهاید، میتوانید از ابزارهای تجاری یا نرمافزار متنباز بسیار محبوب (که بسیاری از ابزارهای تجاری بر اساس آن ساخته شدهاند) استفاده کنید. برای مثال، ممکن است بخواهید ابزار حاشیه نویسی بینایی رایانه (CVAT) را که توسط اینتل توسعه یافته و منبع باز است، بررسی کنید.
دادههای اسمی(Nominal Data) یکی از اساسیترین انواع دادهها در تجزیه و تحلیل دادهها است. شناسایی و تفسیر آن در بسیاری از زمینهها از جمله آمار، علوم کامپیوتر، روانشناسی و بازاریابی ضروری است. این مقاله ویژگیها، کاربردها و تفاوتهای دادههای اسمی
حاشیهنویسی داده به الگوریتمهای یادگیری ماشین اجازه میدهد تا اطلاعات را درک و تفسیر کنند. حاشیهنویسیها برچسبهایی هستند که دادهها را شناسایی و طبقهبندی میکنند یا قطعات مختلف اطلاعات را با یکدیگر مرتبط میکنند. الگوریتمهای هوش مصنوعی از آنها به
مکانهای باستانشناسی ممکن است ثابت باشند، اما فرهنگهایی که آنها را تولید کردهاند، پویا و متنوع بودند. برخی از آنها کاملاً عشایری بودند و مرتباً موقعیت خود را تغییر میدادند. برخی از آنها فواصل بسیار زیادی را مهاجرت کردند، در
تشخیص اشیاء یک کار مهم در بینایی کامپیوتر است که با رسم کادرهای محدود کننده در اطراف اشیاء شناسایی شده، مکان یک شی را در یک تصویر شناسایی و مکانیابی میکند. اهمیت تشخیص اشیاء را نمیتوان به اندازه کافی بیان
تصویربرداری چند طیفی تکنیکی است که نور را در طیف وسیعی از باندهای طیفی، فراتر از آنچه چشم انسان میتواند ببیند، از جمله نور مادون قرمز و ماوراء بنفش، ثبت میکند. این رویکرد به طور قابل توجهی از تصویربرداری رنگی
یادگیری ماشین (Machine Learning) و علم داده (Data Science) موضوعاتی هستند که در تمامی بخشهای فناوری اطلاعات در مورد آن بحث و گفتگو وجود دارد. امروزه همه چیز در حال خودکار شدن است، و برنامههای کاربردی نیز به سرعت در