
زمان تخمینی مطالعه: 7 دقیقه
PyTorchVideo یک کتابخانه یادگیری عمیق کارآمد، منعطف و ماژولار جدید برای تحقیقات در حوزه درک ویدیو است. این کتابخانه با استفاده از PyTorch ساخته شده است و مجموعه کاملی از ابزارهای درک ویدیو را پوشش میدهد، و به انواع برنامههای کاربردی برای درک ویدیو قابلیت مقیاس شدن را دارد. در این مقاله یک نمای کلی آسان برای درک PyTorchVideo ارائه خواهیم داد و موارد زیر را پوشش میدهیم:
- درک ویدیو با هوش مصنوعی
- PyTorchVideo چیست؟
- ویژگیهای کلیدی PyTorchVideo کدام است؟
- PyTorchVideo برای چه مواردی میتواند استفاده شود؟
چه نیازی به درک ویدیو با هوش مصنوعی وجود دارد؟
ضبط، ثبت، ذخیره و تماشای ویدیوها به بخشی از زندگی روزمره ما انسانها تبدیل شده است. با ظهور اینترنت اشیا (IoT)، حسگرها و دوربینهای متصل، حجم دادههای تولید شده در سطح جهانی در حال انفجار است. با این حجم عظیم از دادههای ویدیویی، اکنون ساختن چارچوبهای یادگیری ماشین و یادگیری عمیق برای درک ویدیو با بینایی کامپیوتری مهمتر از همیشه است.
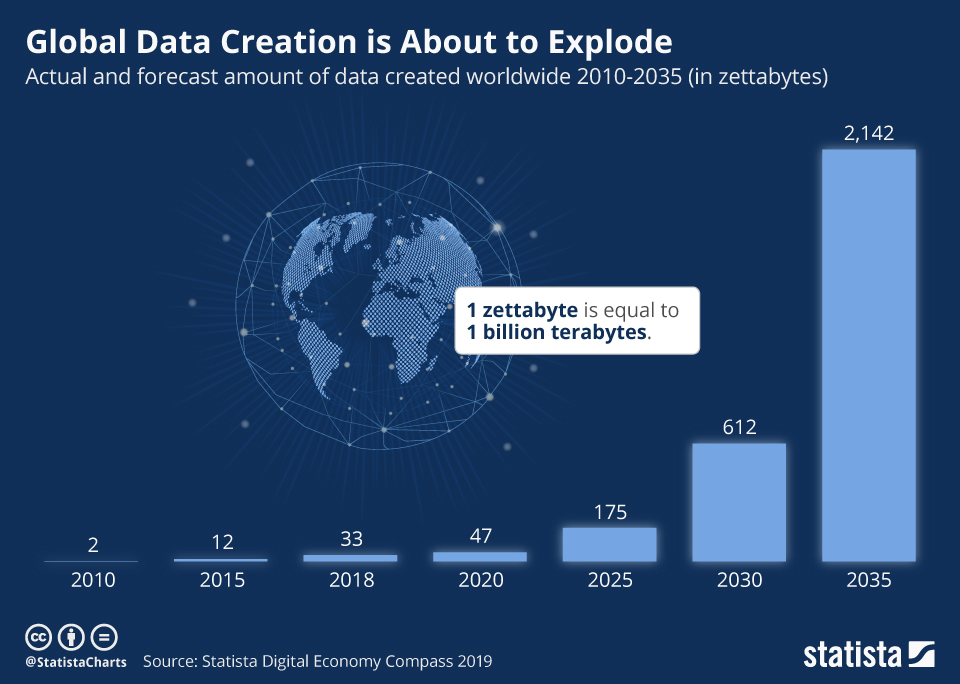
فناوری هوش مصنوعی جدید راههایی را برای تجزیه و تحلیل موثر دادههای بصری و توسعه برنامههای کاربردی هوشمند و سیستمهای بینایی هوشمند جدید ارائه میدهد. موارد استفاده شامل نظارت تصویری، شهر هوشمند، ورزش و تناسب اندام، یا برنامههای کاربردی تولید هوشمند است. با رشد محبوبیت روزافزون یادگیری عمیق، محققان پیشرفتهای قابل توجهی در درک ویدیو از طریق تقویت دادههای پیشرفته، معماری شبکههای عصبی انقلابی، شتاب مدل هوش مصنوعی و روشهای آموزشی بهتر داشتهاند.
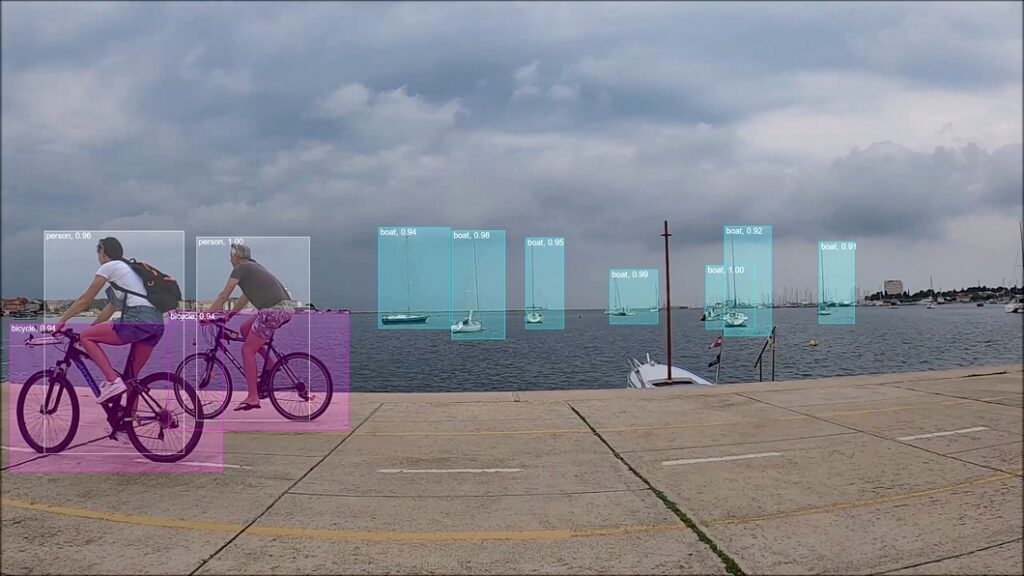
در هر صورت، حجم دادهای که ویدیو تولید میکند، درک ویدیو را به چالش بزرگی بدل کرده است، به همین دلیل است که راهحلهای مؤثر برای اجرا و پیاده سازی بیاهمیت میباشند. تاکنون چندین کتابخانه درک ویدیوی معروف منتشر شدهاند که پیادهسازی مدلهای پردازش ویدیویی را ارائه میدهند، مانند Gluon-CV، PySlowFast، MMAction2 و MMAction. اما برخلاف سایر کتابخانههای ماژولار که میتوانند به پروژههای مختلف وارد شوند، این کتابخانهها بر اساس گردش کار آموزشی ساخته شدهاند که پذیرش آنها را فراتر از موارد استفاده متناسب با یک پایگاه کد خاص محدود میکند. به همین دلیل است که محققان برای غلبه بر محدودیتهای اصلی جامعه تحقیقاتی ویدیویی هوش مصنوعی، چارچوبی برای درک ویدیوی ماژولار و متمرکز بر ویژگیها ایجاد کردند.
PyTorchVideo چیست؟
PyTorchVideo یک کتابخانه یادگیری عمیق منبع باز است که توسط فیس بوک AI توسعه یافته و برای اولین بار در سال 2021 منتشر شد. این کتابخانه مجموعهای از اجزای ماژولار، کارآمد و قابل تکرار را برای کارهای مختلف درک ویدیو، از جمله تشخیص اشیا، طبقهبندی صحنه، و یادگیری خود نظارتی در اختیار توسعه دهندگان قرار میدهد. این کتابخانه با مجوز منبع باز Apache 2.0 توزیع شده است و در GitHub در دسترس است. همچنین اسناد رسمی مربوط به این کتابخانه را میتوان در وب سایت PyTorchVideo یافت. کتابخانه یادگیری ماشینی PyTorch Video مزایای زیر را به شرح زیر ارائه میدهد:
- طبقهبندی ویدیوی بیدرنگ: از طریق اجرا بر روی دستگاه، پشتیبانی شتاب سختافزاری
- طراحی ماژولار: با یک اینترفیس توسعه قابل بسط برای مدلسازی ویدیو با استفاده از پایتون
- مجموعه دادههای قابل تکرار و مدلهای ویدیویی از پیش آموزش دیده: مدلها به طور دقیق پشتیبانی و محک زده میشوند
- ویژگیهای ML درک کامل ویدیویی: شامل مجموعه دادههای ثابت تا مدلهای هوش مصنوعی پیشرفته
- چندین روش ورودی: مانند IMU، بصری، جریان نوری و دادههای صوتی
- وظایف بینایی: از جمله یادگیری خود نظارتی (SSL)، وظایف بینایی سطح پایین و طبقهبندی یا تشخیص انسانی
ویژگیهای کلیدی PyTorchVideo
کتابخانه PyTorchVideo بر اساس سه اصل اساسی ماژولار بودن، سازگاری و شخصیسازی است.
- ماژولاریتی: PyTorchVideo باید بر ویژگیها متمرکز باشد و ویژگیهای منحصر به فرد plug-and-play را ارائه دهد که قادر به ترکیب و تطبیق در هر حالتی باشد. این موضوع را میتوان با ساختاربندی مدلها، تبدیل دادهها و مجموعه دادهها به طور جداگانه، تنها با اعمال سازگاری از طریق دستورالعملهای نامگذاری آرگومان مشترک، به دست آورد. به عنوان مثال، در ماژول pytorchvideo.data، همه مجموعه دادهها آرگومان data_path را ارائه میدهند. یا در مورد ماژول pytorchvideo.models از نام dim_in در مورد ابعاد ورودی استفاده میشود. این نوع duck-typing انعطافپذیری و توسعهپذیری بالایی را برای کاربردهای جدید ارائه میدهد.
- سازگاری: کتابخانه PyTorchVideo به گونهای ساخته شده است که میتواند با سایر کتابخانهها و چارچوبهای خاص دامنه سازگار باشد. در مقایسه با چارچوبهای ویدیویی موجود، این کتابخانه به یک سیستم پیکربندی خاص وابسته نیست. PyTorchVideo از آرگومانهای کلیدواژه به عنوان یک “سیستم پیکربندی ساده” استفاده میکند تا سازگاری خود را با کتابخانههای اختصاصی Python با سیستمهای پیکربندی دلخواه افزایش دهد. از سوی دیگر، این کتابخانه از قابلیت همکاری با سایر چارچوبهای استاندارد دامنه خاص با تثبیت انواع تانسور مبتنی بر مدالیته متعارف (ویدئو، صدا، طیفنگارها و غیره) پشتیبانی میکند.
- قابلیت سفارشیسازی: یکی از موارد استفاده اساسی این کتابخانه این است که از جدیدترین رویکردهای تحقیقاتی پشتیبانی میکند. به این ترتیب، محققان و دانشمندان به راحتی میتوانند کار خود را بدون تغییر معماری یا بازسازی انجام دهند. بنابراین، سازندگان PyTorchVideo این کتابخانه را برای کاهش هزینههای اضافه مؤلفهها یا ماژولهای فرعی جدید طراحی کردند. این کتابخانه دارای یک اینترفیس(رابط) ترکیبی متشکل از کلاسهای اسکلت تزریقی است. این با یک رابط که پیادهسازیهای تکرارپذیر را از طریق کلاسهای ترکیبی ایجاد میکند ترکیب میشود. در نتیجه، محققان میتوانند به سادگی اجزای فرعی جدیدی را به ساختار مدلهای بزرگتر مانند ResNet متصل کنند.
ویژگیهای اصلی PyTorchVideo به طور خلاصه
کتابخانه PyTorchVideo در حال حاضر ویژگیهایی را ارائه میکند که میتوان از آنها برای تعداد بیشماری از برنامههای کاربردی درک ویدیو استفاده کرد. این کتابخانه شامل پیادهسازیهای قابل استفاده مجدد از مدلهای محبوب برای طبقهبندی ویدیو، تشخیص رویداد، جریان نوری، محلیسازی کنش انسانی در ویدیو، و الگوریتمهای یادگیری خود نظارت است.
کتابخانه PyTorchVideo یک محیط (شتابدهنده) برای استقرار سخت افزاری مدلها برای استنتاج سریع بر روی دستگاههای لبه فراهم میکند، مفهومی که به عنوان Edge AI شناخته میشود. با ویژگیهای مختلف، PyTorchVideo Accelerator یک محیط کامل برای طراحی و استقرار مدلهای سختافزاری بهینهسازی شده برای استنتاج سریع فراهم میکند. PyTorchVideo فیسبوک AI پتانسیل زیادی در حوزه درک ویدیو دارد و برخی از ویژگیهای اصلی آن عبارتند از:
- دسترسی به مجموعهای از ابزارها و اسکریپتهای استاندارد برای پردازش ویدیو، از جمله استخراج جریان بهینه، ردیابی و رمزگشایی.
- محققان میتوانند معماریهای ویدیویی جدیدی را از طریق مدلهای ویدیویی و وزنهای از پیش آموزشدیدهشده با ویژگیهای متناسب ایجاد کنند.
- طراحی مدل بهینهشده و آگاه از سختافزار و استقرار مدل با سرعت بالا بر روی دستگاه از طریق بلوکهای سازنده مؤثر حاصل میشود.
- پشتیبانی از چندین کار پایین دستی مانند یادگیری خود نظارتی (SSL)، طبقهبندی کنش، تشخیص رویداد صوتی و تشخیص اقدام.
- سازگاری با بسیاری از مجموعه دادهها و وظایف برای محکزدن مدلهای مختلف ویدیویی با استفاده از پروتکلهای ارزیابی مختلف امکانپذیر است.