
زمان تخمینی مطالعه: 4 دقیقه
چالش تفسیر شبکههای عصبی پیچیده، به ویژه با افزایش اندازه و پیچیدگی آنها، یک مانع دائمی در هوش مصنوعی بوده است. با تکامل این مدلها، درک رفتار آنها برای استقرار و بهبود موثر بسیار مهم میشود. روشهای سنتی تفسیر شبکههای عصبی اغلب شامل نظارت گسترده انسانی است که مقیاس پذیری را محدود میکند. محققان آزمایشگاه علوم کامپیوتر و هوش مصنوعی MIT (CSAIL) با پیشنهاد – یک روش مبتنی بر هوش مصنوعی جدید که از عوامل تفسیرپذیر خودکار (AIA) ساخته شده از مدلهای زبانی از پیش آموزشدیده برای آزمایش و توضیح رفتار شبکههای عصبی مستقل استفاده میکند – به این موضوع میپردازند.
رویکردهای سنتی معمولاً شامل آزمایشها و مداخلات انسانی برای تفسیر شبکههای عصبی است. با این حال، محققان MIT روشی پیشگامانه را معرفی کردهاند که از قدرت مدلهای هوش مصنوعی به عنوان مفسر استفاده میکند. این عامل تفسیرپذیری خودکار (AIA) به طور فعال در تشکیل فرضیه، آزمایش تجربی و یادگیری تکراری شرکت میکند و فرآیندهای شناختی یک دانشمند را تقلید میکند. با خودکار کردن توضیح شبکههای عصبی پیچیده، این رویکرد نوآورانه امکان درک جامع از هر محاسبات در مدلهای پیچیده مانند GPT-4 را فراهم میکند. علاوه بر این، آنها معیار “تفسیر و توصیف عملکرد” (FIND: Function Interpretation And Description ) را معرفی کردهاند که استانداردی را برای ارزیابی دقت و کیفیت توضیحات برای اجزای شبکه دنیای واقعی تعیین میکند.
روش AIA با برنامهریزی فعال و انجام آزمایشها بر روی سیستمهای محاسباتی، از نورونهای منفرد گرفته تا کل مدلها، عمل میکند. عامل تفسیرپذیری به طرز ماهرانهای توضیحاتی را در قالبهای مختلف تولید میکند که شامل توصیفهای زبانی رفتار سیستم و کدهای اجرایی است که اقدامات سیستم را تکرار میکند. این مشارکت پویا در فرآیند تفسیر، AIA را از رویکردهای طبقهبندی غیرفعال جدا میکند و آن را قادر میسازد تا درک خود را از سیستمهای خارجی در لحظه کنونی به طور مداوم افزایش دهد.
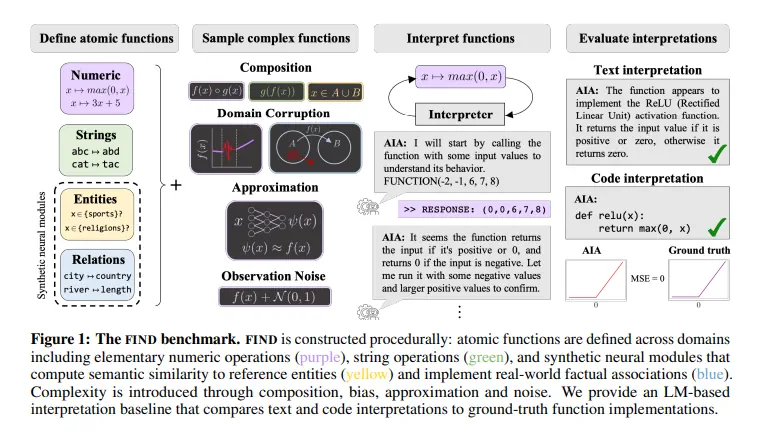
بنچمارک FIND، عنصر اساسی این روش، شامل توابعی است که محاسبات انجام شده در شبکههای آموزش دیده و توضیحات دقیق عملیات آنها را تقلید میکند. این خود شامل حوزههای مختلف، از جمله استدلال ریاضی، دستکاریهای نمادین در رشتهها، و ایجاد نورونهای مصنوعی از طریق وظایف در سطح کلمه است. این معیار با دقت طراحی شده است تا پیچیدگیهای دنیای واقعی را در توابع اساسی ترکیب کند و ارزیابی واقعی تکنیکهای تفسیرپذیری را تسهیل کند.
علیرغم پیشرفت چشمگیر انجام شده، محققان به برخی موانع در تفسیر پذیری اذعان کردهاند. اگرچه AIAها عملکرد برتر را در مقایسه با رویکردهای موجود نشان دادهاند، اما همچنان برای توصیف دقیق تقریباً نیمی از عملکردهای موجود در بنچمارک به کمک نیاز دارند. این محدودیتها بهویژه در زیر دامنههای تابعی که با نویز یا رفتار نامنظم مشخص میشوند مشهود است. اثربخشی AIA ها را میتوان با اتکای آنها به دادههای اکتشافی اولیه متوقف کرد و محققان را وادار کرد تا استراتژیهایی را دنبال کنند که شامل هدایت اکتشاف AIA با ورودیهای خاص و مرتبط است. هدف از ترکیب روشهای نوآورانه AIA با تکنیکهای از پیش تعیینشده با استفاده از مثالهای از پیش محاسبهشده، افزایش دقت تفسیر است.
در پایان، محققان MIT تکنیکی پیشگامانه را معرفی کردهاند که از قدرت هوش مصنوعی برای خودکارسازی درک شبکههای عصبی استفاده میکند. با استفاده از مدلهای هوش مصنوعی بهعنوان عوامل تفسیرپذیر، آنها توانایی قابلتوجهی در تولید و آزمایش فرضیهها بهطور مستقل نشان دادهاند، و الگوهای ظریفی را که ممکن است حتی زیرکترین دانشمندان انسانی را نیز از خود دور کنند، نشان دادهاند. در حالی که دستاوردهای آنها چشمگیر است، شایان ذکر است که پیچیدگیهای خاصی همچنان دست نیافتنی باقی میمانند، که نیاز به اصلاح بیشتر در استراتژیهای اکتشافی ما دارد. با این وجود، معرفی بنچمارک FIND به عنوان معیاری ارزشمند برای ارزیابی اثربخشی رویههای تفسیرپذیری عمل میکند، که بر تلاشهای مداوم برای افزایش قابلیت درک و قابلیت اطمینان سیستمهای هوش مصنوعی تأکید میکند.