
زمان تخمینی مطالعه: 8 دقیقه
آیا تا به حال به این فکر کرده اید که دست به اجرای LLM محلی و VLM بر روی رزبری پای 5 خود بزنید؟ احتمالاً این کار را کردهاید، اما فکر راهاندازی کارها از ابتدا، نیاز به مدیریت محیط اجرا، دانلود وزنهای مناسب مدل، و شک دائمی در مورد اینکه آیا دستگاه شما حتی میتواند مدل را مدیریت کند یا خیر، احتمالاً شما را کمی دچار خلل کرده است.
امکان سنجی پروژه
LLMها(مدلهای زبان بزرگ) در لبه علم قرار داشته و اجرای آنها بر روی دستگاهی مثل رزبری پای در این برهه از زمان بسیار دور از ذهن به نظر میرسد. اما این مورد خاص که بتوانیم از یک دستگاه لبه(Edge) برای پردازش LLM ها بهره بگیریم باید به مرور زمان به بلوغ برسد، و ما قطعاً شاهد استفاده از راهحلهای جذاب با یک راهحل هوش مصنوعی مولد تمام محلی خواهیم بود که روی دستگاه در لبه اجرا میشود. در واقع میتوان گفت که این تلاش مثالی از آزمودن محدودیتها برای دیدن آنچه ممکن است میباشد. اگر بتوان این سیستمها را بر روی چنین بردهایی اجرا کرد بنابراین میتوان آن را در هر سطحی مابین رزبری پای و سرور بزرگ و قدرتمند GPU انجام داد. آیا میتوان اقدام به اجرای LLM محلی و VLM بر روی رزبری پای 5 کرد؟ سوالی بزرگ است.
به طور سنتی، هوش مصنوعی لبه(Edge) ارتباط نزدیکی با بینایی کامپیوتر دارد. کاوش در استقرار LLMها و VLMها(مدلهای زبان بینایی) در لبه، بعد هیجان انگیزی را به این زمینه اضافه میکند که به تازگی در حال ظهور است.مهمتر از همه، این پروژه در واقع تلاشی برای تست قابلیت رزبری پای 5 برای اجرای چنین سیستمی است.بنابراین، دست به دامان اولاما(Ollama) شدیم!!!!
اولاما(Ollama) چیست؟
Ollama به عنوان یکی از بهترین راه حلها برای اجرای LLMهای محلی بر روی رایانه شخصی بدون نیاز به دست و پنجه نرم کردن با مشکل تنظیم پارامترها از ابتدا است. در این برنامه تنها با چند دستور میتوان همه چیز را بدون هیچ مشکلی راه اندازی کرد. در اولاما همه چیز مستقل بوده و بر اساس تجربه در چندین دستگاه و مدل به طرز شگفت انگیزی کار میکند. حتی یک REST API را برای استنباط مدل نشان میدهد، بنابراین میتوانید آن را روی برد رسپری پای اجرا کنید و در صورت تمایل آن را از سایر برنامهها و دستگاههای خود فراخوانی کنید.
همچنین رابط کاربری اولاما(Ollama Web UI) هم وجود دارد که یک بخش زیبا از UI/UX هوش مصنوعی است که به طور یکپارچه با اولاما برای کسانی که از رابطهای خط فرمان نگران هستند اجرا میشود. که اساساً یک رابط ChatGPT محلی است. این دو قطعه نرم افزاری منبع باز چیزی را ارائه میدهند که بهترین تجربه از میزبانی محلی LLM در حال حاضر است.هم Ollama و هم Ollama Web UI از VLMهایی مانند LLaVA نیز پشتیبانی میکنند، که قادر به گشودن درهای بیشتری برای استفاده از هوش مصنوعی مولد در ابزار لبه مانند رزبری پای است.
الزامات فنی
تنها چیزی که نیاز دارید به شرح ادامه است:
- رزبری پای 5 (یا 4 برای نصب با سرعت کمتر) – میزان رم 8 گیگابایتی را انتخاب کنید تا متناسب با مدل های 7B باشد.
- کارت SD – حداقل 16 گیگابایت، هر چه اندازه بزرگتر باشد، مدلهای بیشتری را میتوانید جا دهید. آن را قبلاً با یک سیستم عامل مناسب مانند Raspbian Bookworm یا Ubuntu بارگذاری کنید
- یک اتصال اینترنتی
همانطور که قبلاً اشاره کردم، اجرای Ollama بر روی رزبری پای در حال حاضر کاری غیر ممکن از لحاظ سخت افزاری است. اساساً، هر دستگاهی قدرتمندتر از رزبری پای، به شرط اینکه توزیع لینوکس را اجرا کند و ظرفیت حافظه مشابهی داشته باشد، از نظر تئوری باید قادر به اجرای Ollama و مدلهای مورد بحث در این مطلب باشد.
- نصب اولاما: برای نصب Ollama روی رزبری پای، از Docker برای حفظ منابع خودداری میکنیم.در ترمینال، وارد کنید:
curl https://ollama.ai/install.sh | shپس از اجرای دستور بالا باید چیزی شبیه به تصویر زیر مشاهده کنید:
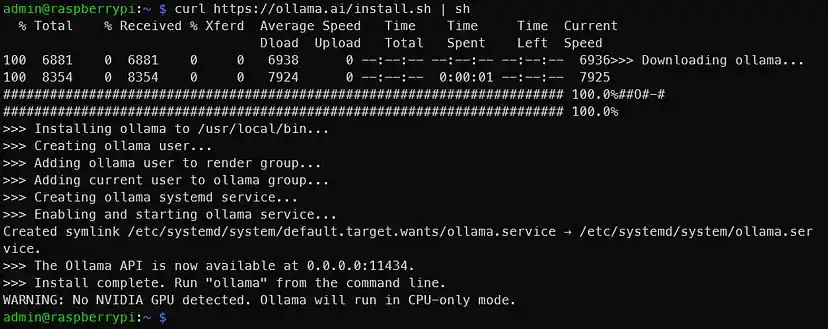
همانطور که خروجی نشان میدهد، به آدرس 0.0.0.0:11434 بروید تا تأیید کنید که اولاما در حال اجرا است. دیدن “هشدار: GPU NVIDIA شناسایی نشده است” اولاما در حالت فقط CPU اجرا می شود» طبیعی است زیرا ما از رزبری پای استفاده میکنیم. اما اگر این دستورالعملها را در مورد چیزی که قرار است پردازنده گرافیکی NVIDIA داشته باشد مشاهده میکنید، حتما چیزی درست پیش نرفته و مشکل وجود دارد.
- اجرای LLM از طریق خط فرمان: برای مشاهده لیستی از مدلهایی که میتوان با استفاده از اولاما اجرا کرد، به کتابخانه رسمی مدل Ollama نگاهی بیندازید. در رزبری پای 8 گیگابایتی، مدلهای بزرگتر از 7B مناسب نیستند. بنابراین از Phi-2، که یک LLM با 2.7B از مایکروسافت تحت مجوز MIT است استفاده کنید. در این مقاله از مدل پیشفرض Phi-2 استفاده شده است، اما از هر یک از برچسبهای دیگر موجود در اینجا استفاده کنید. به صفحه مدل Phi-2 نگاهی بیندازید تا ببینید چگونه میتوانید با آن تعامل کنید. دستورات زیر را در ترمینال، اجرا کنید:
ollama run phiهنگامی که چیزی شبیه به خروجی زیر مشاهده کردید، شما یک LLM در حال اجرا بر روی رزبری پای دارید!
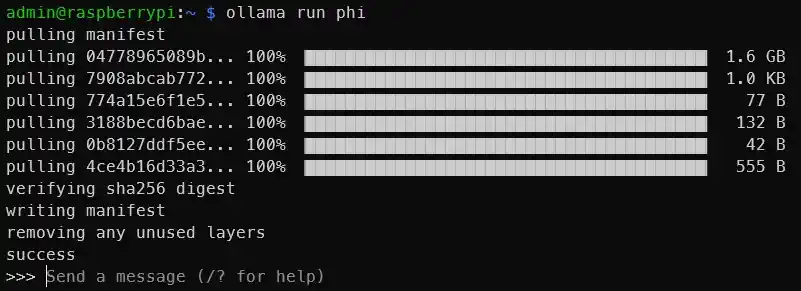
میتوانید مدلهای دیگری مانند Mistral، Llama-2 و غیره را امتحان کنید، فقط مطمئن شوید که فضای کافی روی کارت SD برای وزنهای مدل وجود دارد. به طور طبیعی، هر چه مدل بزرگتر باشد، خروجی کندتر خواهد بود. در Phi-2 2.7B، میتوانم حدود 4 توکن در ثانیه دریافت کنم. اما با Mistral 7B، سرعت تولید به حدود 2 توکن در ثانیه کاهش مییابد. تر توکن تقریباً معادل یک کلمه است.
اکنون ما LLMهایی داریم که روی رزبری پای اجرا میشوند، اما هنوز کارمان تمام نشده است. در ادامه Ollama Web UI را اجرا خواهیم کرد.
- نصب و اجرای Ollama Web UI: ما باید دستورالعملهای موجود در مخزن رسمی Ollama Web UI در گیت هاب را دنبال کنیم تا آن را بدون Docker نصب کنیم. این کتابخه حداقل Node.js ورژن 20.10 به بالا را توصیه میکند. همچنین پایتون باید حداقل ورژن 3.11 باشد که پیشتر در سیستم عامل rasbian برد رزبری موجود است.ابتدا باید Node.js را نصب کنیم:
curl -fsSL https://deb.nodesource.com/setup_20.x | sudo -E bash - &&\
sudo apt-get install -y nodejsدر صورت نیاز برای خوانندگان این متن در آینده، ورژن را به یک نسخه مناسب تر تغییر دهید. سپس بلوک کد زیر را اجرا کنید..
git clone https://github.com/ollama-webui/ollama-webui.git
cd ollama-webui/
# Copying required .env file
cp -RPp example.env .env
# Building Frontend Using Node
npm i
npm run build
# Serving Frontend with the Backend
cd ./backend
pip install -r requirements.txt --break-system-packages
sh start.shاگر همه چیز درست پیش برود، باید بتوانید از طریق آدرس http://0.0.0.0:8080 در رزبری پای، دسترسی داشته باشید.
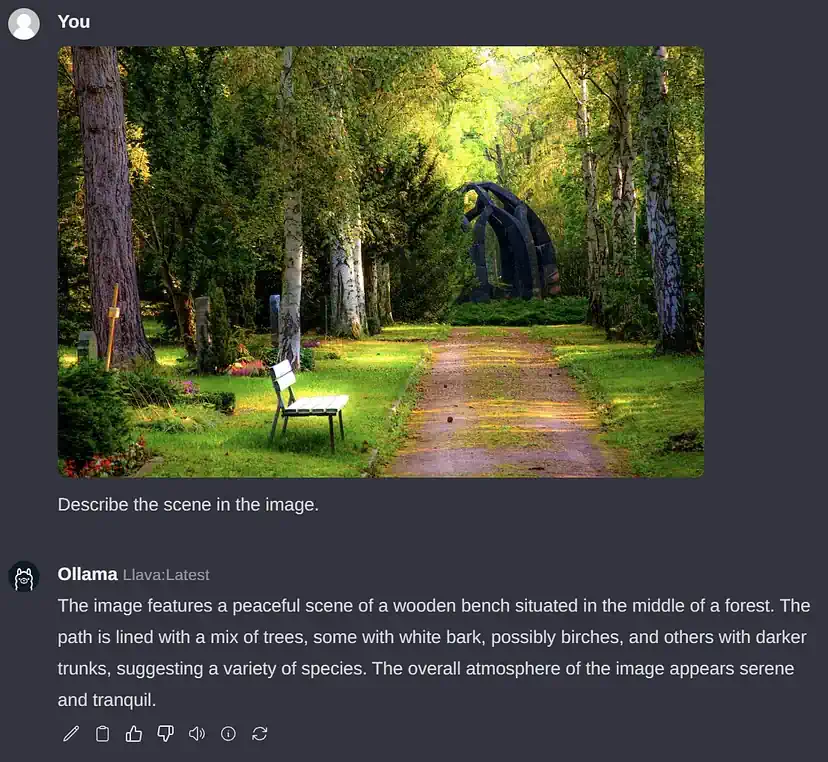
- اجرای VLMها از طریق Ollama Web UI: همانطور که در ابتدای این مقاله اشاره کردم، ما میتوانیم VLMها را نیز اجرا کنیم. بیایید LLaVA را اجرا کنیم، یک VLM منبع باز محبوب که اتفاقاً توسط Ollama نیز پشتیبانی میشود. برای انجام این کار، وزنها را با کشیدن «llava» از طریق رابط دانلود کنید. متأسفانه، بر خلاف LLMها، زمان زیادی طول میکشد تا تنظیمات تصویر را در رزبری پای انجام دهیم تا سیستم شروع به تفسیر کند. پردازش تصویر در مثال زیر حدود 6 دقیقه طول کشید. بیشتر اوقات این تاخیر احتمالاً به این دلیل است که جنبه تصویری چیزها هنوز به درستی بهینه نشده است، اما این قطعاً در آینده تغییر خواهد کرد. در این سیستم سرعت تولید توکن حدود 2 توکن در ثانیه است.
نتیجه گیری
در انتها برای جمع بندی باید گفت که موفق شدهایم از Ollama و Ollama Web UI برای اجرای LLM محلی و VLM بر روی رزبری پای 5 استفاده کنیم. امید است که روز به روز شاهد شکوفایی بیشتر این حوزه باشیم.