ظهور بینایی کامپیوتر تا حد زیادی مبتنی بر موفقیت روشهای یادگیری عمیق است که از شبکههای عصبی کانولوشنال (CNN) استفاده میکنند. با این حال، این شبکههای عصبی به شدت به دادههای آموزشی زیادی برای جلوگیری از برازش بیش از حد و عملکرد ضعیف مدل وابسته هستند. متأسفانه، در بسیاری از موارد مانند برنامههای کاربردی در دنیای واقعی، دادههای محدودی در دسترس است و جمع آوری دادههای آموزشی کافی بسیار چالش برانگیز و پرهزینه است. از این رو تقویت داده تصویر برای کارهای بینایی ماشین دارای اهمیت بالایی است.
تقویت داده Data Augmentation چیست؟
تقویت داده مجموعهای از تکنیکهایی است که اندازه و کیفیت مجموعه دادههای آموزشی یادگیری ماشین را افزایش میدهد تا بتوان مدلهای یادگیری عمیق بهتری را با آنها آموزش داد.
Data Augmentation به طور مصنوعی مجموعه دادهها را با استفاده از تبدیل دادههای حفظ برچسب(label-preserving) تقویت میکند.
تکنیکهای محبوب تقویت داده چیست؟
الگوریتمهای تقویت داده تصویر شامل تبدیلهای هندسی، تقویت فضای رنگی، فیلتر کردن هسته، ترکیب تصاویر، پاک کردن تصادفی، تقویت فضای ویژگی، آموزش خصمانه، شبکههای متخاصم مولد (GAN)، فرا یادگیری و انتقال سبک عصبی است.
کاهش بیش از حد برازش در یادگیری عمیق
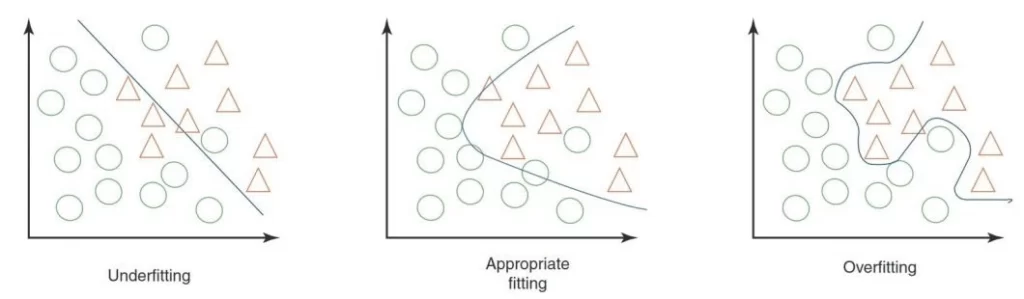
پیشرفتهای اخیر در فناوری یادگیری عمیق با پیشرفت معماریهای شبکه عمیق، محاسبات قدرتمند و دسترسی به دادههای بزرگ انجام شده است. شبکههای عصبی کانولوشنال عمیق (CNN) در بسیاری از وظایف بینایی کامپیوتری مانند طبقهبندی تصویر، تشخیص اشیاء و بخشبندی تصویر به موفقیت زیادی دست یافتهاند. یکی از دشوارترین چالشها تعمیمپذیری مدلهای یادگیری عمیق است که تفاوت عملکرد یک مدل را هنگام ارزیابی دادههای قبلاً دیده شده (دادههای آموزشی) در مقابل دادههایی که قبلاً هرگز ندیدهاند (دادههای آزمایشی) توصیف میکند. مدلهای با تعمیمپذیری ضعیف، دادههای آموزشی را بیش از حد برازش دادهاند (Overfitting). برای ساخت مدلهای یادگیری عمیق مفید، Data Augmentation یک روش بسیار قدرتمند برای کاهش بیشبرازش با ارائه مجموعهای جامعتر از نقاط داده ممکن برای به حداقل رساندن فاصله بین مجموعههای آموزشی و آزمایشی است.
برازش بیش از حد در مقابل عدم تناسب(Underfitting) در یادگیری ماشین.
تقویت داده به صورت مصنوعی
رویکرد تقویت داده از ریشه مسئله که همانا دادههای آموزشی هستند شروع میگردد. ایده اصلی این است که اطلاعات بیشتری را میتوان از مجموعه دادههای تصویر اصلی از طریق ایجاد تقویتها به دست آورد. این افزایشها بهطور مصنوعی اندازه مجموعه دادههای آموزشی را با تاب برداشتن(Warping) یا نمونهبرداری بیشازحد افزایش میدهند. در ادامه روشهای مختلف این حوزه آورده شده است:
افزایش تاب دادهها: تصاویر موجود را با حفظ برچسب (اطلاعات حاشیهنویسی) تغییر دهید. این شامل تقویتهایی مانند تبدیلهای هندسی و رنگ، پاک کردن تصادفی، آموزش خصمانه و انتقال سبک عصبی است.
افزایش نمونه برداری بیش از حد: نمونههای داده مصنوعی ایجاد کنید و آنها را به مجموعه آموزشی اضافه کنید. این شامل اختلاط تصاویر، افزایش فضای ویژگی و شبکههای متخاصم مولد (GAN) است.
رویکردهای ترکیبی: این روشها را میتوان به صورت ترکیبی اعمال کرد، برای مثال، نمونههای GAN را میتوان با برش تصادفی روی هم قرار داد تا مجموعه دادهها را بیشتر کند.
نمونههای تقویت داده تصویر.
مجموعه دادههای بزرگتر
به طور کلی، مجموعه دادههای بزرگتر منجر به عملکرد بهتر مدل یادگیری عمیق میشود. با این حال، جمعآوری مجموعههای داده بسیار بزرگ میتواند بسیار دشوار باشد و به تلاش دستی عظیمی برای جمعآوری و برچسبگذاری دادههای تصویر نیاز دارد. چالش مجموعه دادههای کوچک و محدود با نقاط داده اندک به ویژه در برنامههای کاربردی واقعی رایج است، به عنوان مثال، در تجزیه و تحلیل تصویر پزشکی در مراقبتهای بهداشتی یا تولید صنعتی. با دادههای بزرگ، شبکههای کانولوشن برای کارهای تجزیه و تحلیل تصویر پزشکی مانند تجزیه و تحلیل اسکن مغز یا طبقهبندی ضایعات پوستی بسیار قدرتمند هستند.
الگوریتم بینایی کامپیوتری برای بازرسی کیفیت محصول تولید ریختهگری با بینایی مبتنی بر هوش مصنوعی.
با این حال، جمع آوری دادهها برای آموزش بینایی کامپیوتر عملی گران و کاری فشرده است. ایجاد مجموعه دادههای تصویری بزرگ به دلیل نادر بودن رویدادها، حریم خصوصی، الزامات کارشناسان صنعت برای برچسب زدن، و هزینه و تلاش دستی مورد نیاز برای ثبت دادههای بصری، به ویژه چالش برانگیز است. این موانع دلیل این است که تقویت داده تصویر به یک زمینه تحقیقاتی مهم تبدیل شده است.
چالشهای جمعآوری دادهها
در جایی که مجموعه دادههای کلی برای بینایی کامپیوتری کافی نیست، اقدام به جمع آوری دادهها مورد نیاز است. جامعه بینایی کامپیوتر منابع زیادی را برای ایجاد مجموعه دادههای عظیمی مانند PASCAL VOC، MS COCO، NYU-Depth V2، و SUN RGB-D با میلیونها نقطه داده حاشیهنویسی شده، سرمایهگذاری کرده است. با این حال، آنها نمیتوانند همه سناریوها را پوشش دهند. این به این معنی است که برای ساخت مجموعه دادهها برای آموزش مداوم یادگیری ماشین (MLOps) به جمع آوری و حاشیهنویسی دادهها نیاز است. با این حال، چندین مشکل در فرآیند جمع آوری دادهها وجود دارد:
برنامهها به دادههای بیشتری نیاز دارند: برنامههای بینایی رایانه در دنیای واقعی شامل وظایف بینایی رایانهای بسیار پیچیده هستند که به مدلها، مجموعه دادهها و برچسبهای پیچیدهتر نیاز دارند.
دسترسی محدود به دادهها: با پیچیدهتر شدن وظایف و گسترش دامنه تغییرات احتمالی، الزامات جمع آوری دادهها چالش برانگیزتر میشود. برخی از سناریوها ممکن است به ندرت در دنیای واقعی رخ دهند، اما مدیریت صحیح این رویدادها حیاتی است.
جمع آوری دادهها دشوار است: فرآیند تولید دادههای آموزشی با کیفیت بالا دشوار و پرهزینه است. ضبط تصویر یا دادههای ویدیویی به ترکیبی از گردش کار، ابزارهای نرم افزاری، دوربینها و سخت افزار محاسباتی نیاز دارد. بسته به برنامههای کاربردی، به متخصصان حوزه نیاز دارد تا دادههای آموزشی مفیدی را جمع آوری کنند.
افزایش هزینهها:حاشیهنویسی تصویر به نیروی انسانی پرهزینه برای ایجاد دادههای واقعی برای آموزش مدل نیاز دارد. هزینه حاشیهنویسی با پیچیدگی کار افزایش مییابد و از برچسبگذاری فریمها به برچسب زدن اشیاء، نقاط کلیدی و حتی پیکسلها در تصویر تغییر میکند. این به نوبه خود نیاز به بررسی یا ممیزی حاشیهنویسی را افزایش میدهد که منجر به هزینههای اضافی برای هر تصویر برچسب زده شده میشود.
حفظ حریم خصوصی دادهها: حفظ حریم خصوصی در بینایی کامپیوتر در حال تبدیل شدن به یک موضوع کلیدی است و جمع آوری دادهها را پیچیدهتر میکند. مقرراتی مانند مقررات حفاظت از دادههای عمومی اتحادیه اروپا (GDPR) یا قانون حفظ حریم خصوصی مصرف کنندگان کالیفرنیا (CCPA) نحوه استفاده از دادههای مصرف کننده را برای آموزش مدلهای یادگیری ماشین محدود میکند. این میزان جمعآوری دادههای دنیای واقعی را محدود میکند و نیاز به آموزش مدلهای یادگیری عمیق در مجموعههای داده کوچکتر را تحریک میکند.
تار کردن صورت افراد حاضر در صحنه برای حفظ حریم خصوصی.
این چالشها نیاز به نقویت داده تصویر را در بینایی کامپیوتر برای دستیابی به عملکرد کافی مدل و بهینهسازی هزینههای بینایی کامپیوتر در کارهای چالش برانگیز مانند تشخیص ویدیو و تصویر را ایجاد میکند.
روشهای محبوب تقویت داده تصویر
آزمایشهای اولیه که اثربخشی تقویت دادهها را نشان میدهند، از تبدیلهای ساده تصویر، به عنوان مثال، چرخش افقی، افزایش فضای رنگی، و برش تصادفی ناشی میشوند. چنین تغییراتی بسیاری از تغییر ناپذیریها را رمزگذاری میکنند که چالشهایی را برای وظایف شناسایی تصویر ایجاد میکنند.
بررسی اجمالی روشهای تقویت داده بینایی کامپیوتری.
روشهای مختلفی برای تقویت داده تصویر وجود دارد:
تبدیلهای هندسی: تقویت داده تصویر با استفاده از چرخش افقی یا عمودی، برش تصادفی، افزایش چرخش، ترجمه برای جابجایی تصاویر به چپ/راست/بالا/پایین، یا تزریق نویز.
اعوجاج رنگ: شامل تغییر روشنایی، رنگ یا اشباع تصاویر است. تغییر توزیع رنگ یا دستکاری هیستوگرام کانال رنگی RGB برای افزایش مقاومت مدل در برابر سوگیریهای(biases) نور استفاده میشود.
فیلترهای کرنل: از تکنیکهای پردازش تصویر برای شفاف کردن و محو کردن تصاویر استفاده میکنند. هدف این روشها افزایش جزئیات در مورد اشیاء مورد علاقه یا بهبود مقاومت در برابر تاری حرکت است.
میکس تصاویر: تکنیکهایی را برای ترکیب تصاویر مختلف با هم با میانگین کردن مقادیر پیکسل آنها برای هر کانال RGB یا برش و الصاق تصادفی تصویر اعمال میکند. در حالی که این روش برای انسان غیرمعمول است، نشان داده است که در افزایش عملکرد مدل موثر است.
حذف اطلاعات: از روشهای پاک کردن تصادفی، برش و پنهانسازی برای پوشاندن قسمتهای تصادفی تصویر و به طور بهینه با استفاده از وصلههای پر شده با مقادیر پیکسل تصادفی استفاده میگردد. حذف یک سطح از اطلاعات برای افزایش مقاومت انسداد در تشخیص تصویر استفاده میشود که در نتیجه افزایش قابل توجهی در استحکام مدل ایجاد میشود.
نتیجه گیری
در بینایی کامپیوتری، شبکههای عصبی مصنوعی عمیق به مجموعهای از دادههای آموزشی برای یادگیری مؤثر نیاز دارند، در حالی که جمعآوری چنین دادههای آموزشی پرهزینه و پر زحمت است. تقویت داده با انبساط مصنوعی مجموعه آموزشی با تبدیلهای حفظ برچسب بر این مسئله غلبه میکند. اخیراً، استفاده گستردهای از تقویت داده تصویر عمومی برای بهبود عملکرد وظیفه شبکه عصبی کانولوشنال (CNN) صورت گرفته است.
دادههای اسمی(Nominal Data) یکی از اساسیترین انواع دادهها در تجزیه و تحلیل دادهها است. شناسایی و تفسیر آن در بسیاری از زمینهها از جمله آمار، علوم کامپیوتر، روانشناسی و بازاریابی ضروری است. این مقاله ویژگیها، کاربردها و تفاوتهای دادههای اسمی
حاشیهنویسی داده به الگوریتمهای یادگیری ماشین اجازه میدهد تا اطلاعات را درک و تفسیر کنند. حاشیهنویسیها برچسبهایی هستند که دادهها را شناسایی و طبقهبندی میکنند یا قطعات مختلف اطلاعات را با یکدیگر مرتبط میکنند. الگوریتمهای هوش مصنوعی از آنها به
مکانهای باستانشناسی ممکن است ثابت باشند، اما فرهنگهایی که آنها را تولید کردهاند، پویا و متنوع بودند. برخی از آنها کاملاً عشایری بودند و مرتباً موقعیت خود را تغییر میدادند. برخی از آنها فواصل بسیار زیادی را مهاجرت کردند، در
تشخیص اشیاء یک کار مهم در بینایی کامپیوتر است که با رسم کادرهای محدود کننده در اطراف اشیاء شناسایی شده، مکان یک شی را در یک تصویر شناسایی و مکانیابی میکند. اهمیت تشخیص اشیاء را نمیتوان به اندازه کافی بیان
تصویربرداری چند طیفی تکنیکی است که نور را در طیف وسیعی از باندهای طیفی، فراتر از آنچه چشم انسان میتواند ببیند، از جمله نور مادون قرمز و ماوراء بنفش، ثبت میکند. این رویکرد به طور قابل توجهی از تصویربرداری رنگی
یادگیری ماشین (Machine Learning) و علم داده (Data Science) موضوعاتی هستند که در تمامی بخشهای فناوری اطلاعات در مورد آن بحث و گفتگو وجود دارد. امروزه همه چیز در حال خودکار شدن است، و برنامههای کاربردی نیز به سرعت در