
زمان تخمینی مطالعه: 16 دقیقه
بینایی کامپیوتر به سرعت به یکی از اجزای اساسی فناوری مدرن تبدیل شده است و صنایعی مانند خرده فروشی، لجستیک، مراقبتهای بهداشتی، رباتیک و وسایل نقلیه خودران را متحول کرده است. همانطور که این مدلها به تکامل خود ادامه میدهند، ارزیابی مدل بینایی کامپیوتر و کارآمدی آنها بسیار مهم است.
معیارهای کلیدی ارزیابی مدل بینایی کامپیوتر
برای ارزیابی یک مدل بینایی کامپیوتر، باید چندین معیار عملکرد کلیدی را درک کنیم. پس از معرفی مفاهیم کلیدی، فهرستی از زمان استفاده برای هر یک از معیارهای عملکرد ارائه خواهیم داد.
- Precision: مفهوم Precision دقت یک معیار عملکرد است که میزان دقت یک مدل را در انجام پیشبینیهای مثبت به صورت کمی نمایش میدهد. این مفهوم به عنوان نسبت پیشبینیهای مثبت واقعی (نمونههای مثبت شناسایی شده به درستی-True Positive) به مجموع موارد مثبت واقعی و مثبت کاذب (مواردی که به اشتباه به عنوان مثبت شناسایی شدهاند- False Positive) تعریف میشود. زمانی که هزینه مثبت کاذب بالا باشد یا هدف به حداقل رساندن تشخیصهای غلط باشد، دقت اهمیت دارد.
- Recall: معیار Recall به عنوان حساسیت یا نرخ مثبت واقعی(True Positive) شناخته میشود، که یک معیار کلیدی در ارزیابی بینایی کامپیوتری و مدل مربوطه است. این معیار به عنوان نسبت پیشبینیهای مثبت واقعی (نمونههای مثبت شناسایی شده به درستی) در بین تمام نمونههای مرتبط (مجموع مثبتهای واقعی و منفیهای کاذب، که نمونههای مثبتی هستند که مدل نتوانسته است شناسایی کند) تعریف میشود. اهمیت Recall در توانایی آن برای اندازهگیری توانایی مدل برای تشخیص همه موارد مثبت است، و آن را به یک معیار مهم در موقعیتهایی تبدیل میکند که موارد مثبت از دست رفته میتواند پیامدهای مهمی داشته باشد.
- امتیاز F1: امتیاز F1 یک معیار عملکرد است که Precision و Recall را در یک مقدار واحد ترکیب میکند و معیار متعادلی از عملکرد یک مدل بینایی کامپیوتری را ارائه میدهد. این معیار به عنوان میانگین هارمونیک Precision و Recall تعریف میشود. اهمیت امتیاز F1 ناشی از سودمندی آن در سناریوهایی با توزیع کلاسی نابرابر یا زمانی که مثبت کاذب و منفی کاذب هزینههای متفاوتی را به همراه دارند. با در نظر گرفتن Precision(دقت پیشبینیهای مثبت) و Recall(توانایی شناسایی همه موارد مثبت)، امتیاز F1 ارزیابی جامعی از عملکرد یک مدل ارائه میکند، بهویژه زمانی که تعادل بین مثبت کاذب و منفی کاذب بسیار مهم است.
- Accuracy: مفهوم Accuracy یک معیار عملکرد اساسی است که در ارزیابی عملکرد بینایی کامپیوتری استفاده میشود. این معیار به عنوان نسبت پیشبینیهای صحیح (هم مثبت و هم منفی واقعی) در بین همه نمونهها در یک مجموعه داده مشخص تعریف میشود. به عبارت دیگر، درصد نمونههایی را که مدل به درستی طبقهبندی کرده است، با در نظر گرفتن طبقات مثبت و منفی اندازهگیری میکند. اهمیت Accuracy از توانایی آن در ارائه معیاری ساده از عملکرد کلی مدل ناشی میشود. این یک ایده کلی از عملکرد مدل در یک کار مشخص، مانند تشخیص شیء، طبقهبندی تصویر، یا بخشبندی میدهد.
- Intersection over Union: معیار IoU به عنوان شاخص جاکارد(Jaccard) شناخته میشود، که معیار مهمی در ارزیابی عملکردی بینایی کامپیوتری استفاده میشود. این امر به ویژه برای وظایف تشخیص اشیاء و محلیسازی مهم است. IoU به عنوان نسبت مساحت همپوشانی بین جعبه مرزی پیشبینی شده و جعبه مرزی حقیقت زمینه(ground truth) به مساحت اتحاد آنها تعریف میشود. به عبارت ساده، IoU درجه همپوشانی بین پیشبینی مدل و هدف واقعی را اندازهگیری میکند، که به صورت مقداری بین 0 و 1 بیان میشود، که 0 نشاندهنده عدم همپوشانی و 1 نشاندهنده تطابق کامل است. اهمیت IoU در توانایی آن برای ارزیابی دقت محلیسازی مدل، ثبت هر دو جنبه تشخیص و موقعیت یک شی در یک تصویر است. با کمی کردن میزان همپوشانی بین جعبههای مرزی حقیقت پیشبینیشده و زمینه، IoU بینشهایی درباره اثربخشی مدل در شناسایی و بومیسازی اشیاء با دقت ارائه میدهد.
- میانگین خطای مطلق (MAE): میانگین خطای مطلق معیاری است که برای اندازهگیری عملکرد مدلهای یادگیری ماشین، مانند مدلهای مورد استفاده در بینایی کامپیوتر، با کمی کردن تفاوت بین مقادیر پیشبینیشده و مقادیر واقعی استفاده میشود. MAE میانگین تفاوتهای مطلق بین پیشبینیها و مقادیر واقعی است. MAE با گرفتن تفاوت مطلق بین مقادیر پیشبینی شده و واقعی برای هر نقطه داده محاسبه میشود و سپس میانگین این تفاوتها در تمام نقاط در مجموعه داده محاسبه میگردد. میانگین خطای مطلق با ارائه یک مقدار واحد که نشان دهنده میانگین خطا در پیشبینیهای مدل است، به ارزیابی دقت مدل بینایی کامپیوتر کمک میکند. مقادیر کمتر MAE نشان دهنده عملکرد بهتر مدل است. از آنجایی که MAE یک معیار خطای مطلق است، تفسیر و درک آن در مقایسه با معیارهای دیگر مانند میانگین مربعات خطا (MSE) آسانتر است.
تکنیکهای ارزیابی مدل بینایی کامپیوتر
چندین تکنیک ارزیابی به درک بهتر عملکرد مدل یادگیری ماشین کمک میکند که در ادامه ذکر شده است:
- ماتریس کانفیوژن: ماتریس Confusion ابزار ارزشمندی برای ارزیابی عملکرد مدلهای طبقهبندی، از جمله مدلهایی است که در وظایف بینایی کامپیوتر استفاده میشوند. این ماتریس جدولی است که تعداد پیشبینیهای مثبت واقعی (TP)، منفی واقعی (TN)، مثبت کاذب (FP) و منفی کاذب (FN) را نشان میدهد که توسط مدل انجام شده است. این چهار جزء نشان میدهد که چگونه نمونهها در کلاسهای مختلف طبقهبندی شدهاند.
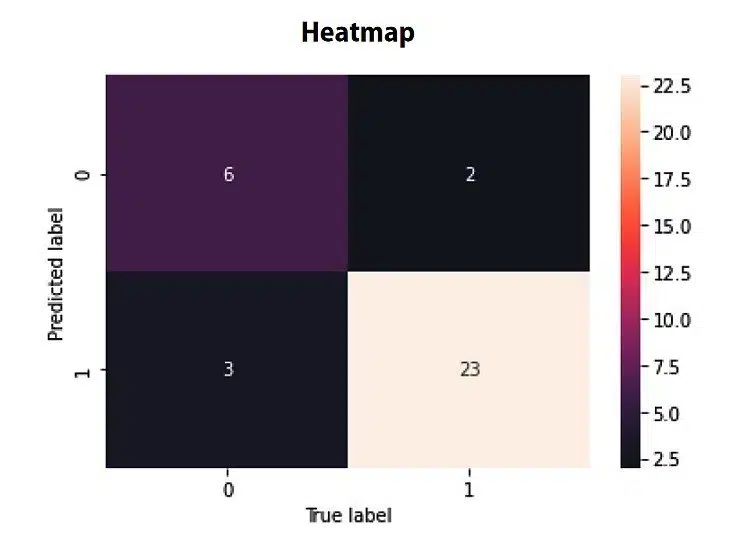
موارد مثبت واقعی (TP) مواردی هستند که به درستی مثبت شناسایی شدهاند و موارد منفی واقعی (TN) مواردی هستند که به درستی به عنوان منفی شناسایی شدهاند. موارد مثبت کاذب (FP) نمونههایی را نشان میدهد که به اشتباه به عنوان مثبت شناسایی شدهاند، در حالی که منفیهای کاذب (FN) مواردی هستند که به اشتباه به عنوان منفی شناسایی شدهاند. تجسم ماتریس Confusion به عنوان یک نقشه حرارتی میتواند تفسیر عملکرد مدل را آسانتر کند. در یک نقشه حرارتی، شدت رنگ هر سلول نشاندهنده تعداد نمونههای ترکیبی مربوط به کلاسهای پیشبینیشده و واقعی است. این تجسم به شناسایی سریع الگوها و مناطقی که مدل ممکن است در آن در حال مبارزه یا برتری باشد کمک میکند.
- مشخصه عملیاتی گیرنده (ROC): منحنی مشخصه عملیاتی گیرنده (ROC) یک معیار عملکردی است که در ارزیابی مدل بینایی کامپیوتری، عمدتاً برای کارهای طبقهبندی استفاده میشود. این معیار به عنوان نموداری از نرخ مثبت واقعی (حساسیت) در برابر نرخ مثبت کاذب برای آستانههای طبقهبندی مختلف تعریف میشود. با نشان دادن مبادله بین حساسیت و ویژگی، منحنی ROC بینشی در مورد عملکرد مدل در طیف وسیعی از آستانهها ارائه میدهد. برای ایجاد منحنی ROC، آستانه طبقهبندی متغیر است و نرخ مثبت واقعی و نرخ مثبت کاذب در هر آستانه محاسبه میشود. منحنی با ترسیم این مقادیر ایجاد میشود و امکان تجزیه و تحلیل بصری عملکرد مدل را در تمایز بین موارد مثبت و منفی فراهم میکند.
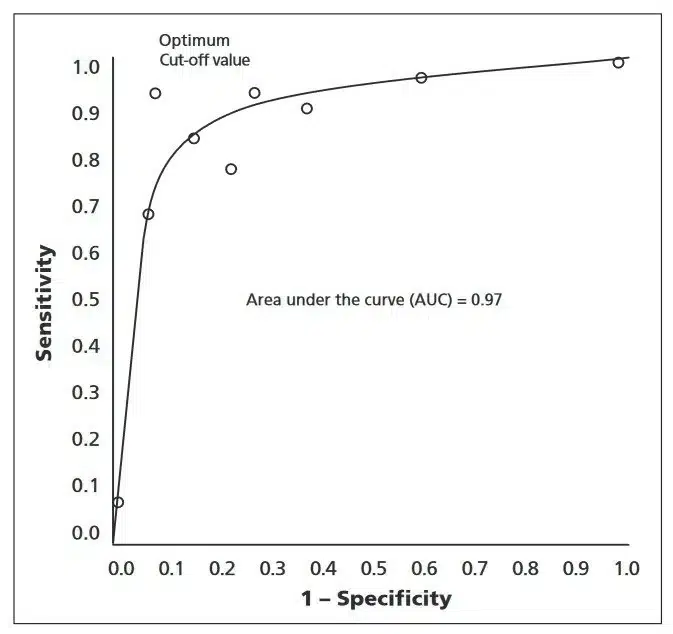
مساحت زیر منحنی (AUC) یک مقیاس خلاصه است که از منحنی ROC مشتق شده است و عملکرد مدل را در تمام آستانهها نشان میدهد. مقدار AUC بالاتر نشاندهنده یک مدل با عملکرد بهتر است، زیرا نشان میدهد که مدل میتواند به طور موثر بین موارد مثبت و منفی در آستانههای مختلف تمایز قائل شود. در کاربردهای دنیای واقعی، مانند سیستم تشخیص سرطان، منحنی ROC میتواند به شناسایی آستانه بهینه برای طبقهبندی بدخیم یا خوشخیم بودن تومور کمک کند. این منحنی به تعیین بهترین آستانه کمک میکند که نیاز به شناسایی صحیح تومورهای بدخیم (حساسیت بالا) را متعادل میکند و در عین حال موارد مثبت کاذب و منفی کاذب را به حداقل میرساند.
- منحنی Precision-Recall: منحنی Precision-Recall یک روش ارزیابی عملکرد است که مبادله بین دقت و یادآوری را برای آستانههای طبقهبندی مختلف نشان میدهد. این مفهوم به تجسم توازن بین توانایی مدل برای پیشبینیهای مثبت صحیح (precision) و توانایی آن برای شناسایی همه موارد مثبت (Recall) در آستانههای مختلف کمک میکند. برای رسم منحنی، آستانه طبقهبندی متفاوت است و precision و Recall در هر آستانه محاسبه میشود. این منحنی عملکرد مدل را در کل محدوده آستانهها نمایش میدهد، و نشان می دهد که چگونه precision و Recall با تغییر آستانه تحت تأثیر قرار میگیرند.
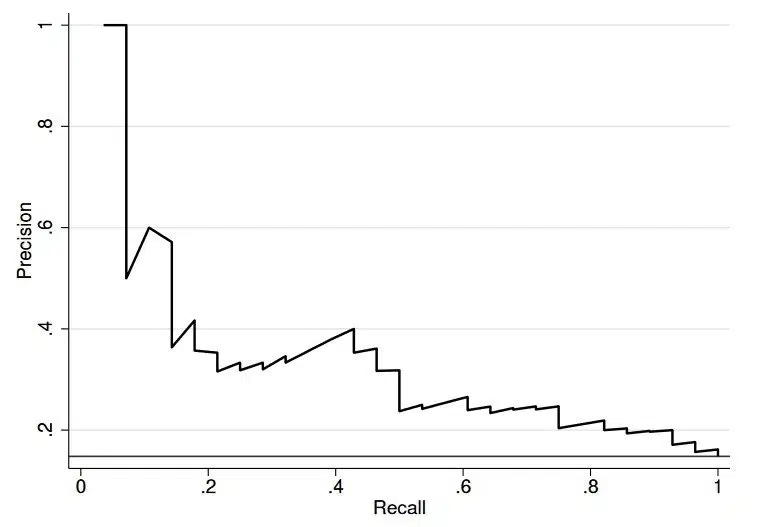
میانگین دقت (Average Precision) یک مقیاس خلاصه است که عملکرد مدل را در تمام آستانهها کمی میکند. مقدار AP بالاتر نشاندهنده یک مدل با عملکرد بهتر است، که نشاندهنده توانایی آن برای دستیابی به precision بالا و Recall همزمان است. AP به ویژه برای مقایسه عملکرد مدلهای مختلف یا تنظیم پارامترهای مدل برای دستیابی به عملکرد بهینه مفید است. یک مثال واقعی از کاربرد عملی منحنی Precision-Recall را میتوان در سیستمهای تشخیص هرزنامه یافت. با تجزیه و تحلیل منحنی، توسعهدهندگان میتوانند آستانه بهینه برای طبقهبندی ایمیلها به عنوان هرزنامه را تعیین کنند، در حالی که بین مثبتهای کاذب (ایمیلهای قانونی که بهعنوان هرزنامه علامتگذاری شدهاند) و منفیهای نادرست (ایمیلهای هرزنامه که شناسایی نمیشوند) تعادل برقرار کنند.
ملاحظات مربوط به دیتاست
ارزیابی مدل بینایی کامپیوتر و میزان عملکرد آن مستلزم بررسی دقیق دیتاست آن مدل را میطلبد:
– تقسیم دیتاست به بخش آموزش و اعتبارسنجی
تقسیم دیتاست کلی به بخشهای آموزش و اعتبار سنجی گامی حیاتی در توسعه و ارزیابی مدل بینایی کامپیوتر است. تقسیم مجموعه داده به زیرمجموعههای جداگانه برای آموزش و اعتبار سنجی به تخمین عملکرد مدل در دادههای دیده نشده کمک میکند. همچنین این کار به رفع مشکل بیشبرازش نیز کمک میکند و اطمینان میدهد که مدل یادگیری ماشین به خوبی بر دادههای جدید تعمیم مییابد. سه مجموعه داده شامل مجموعه آموزش، اعتبار سنجی و مجموعه تست، اجزای اساسی فرآیند توسعه مدل یادگیری ماشین هستند:
- مجموعه آموزشی Training: مجموعهای از نقاط داده برچسبگذاری شده که برای آموزش مدل، تنظیم پارامترها و الگوهای یادگیری و ویژگیهای آن استفاده میشود.
- مجموعه اعتبار سنجی Validation: یک مجموعه داده جداگانه برای ارزیابی مدل در طول توسعه، که برای تنظیم هایپرپارامتر و انتخاب مدل بدون معرفی بایاس از مجموعه تست استفاده میشود.
- مجموعه تست Test: یک مجموعه داده مستقل برای ارزیابی عملکرد نهایی مدل و توانایی تعمیم در دادههای دیده نشده.
تقسیم مجموعه دادههای یادگیری ماشین برای جلوگیری از آموزش مدل بر روی همان دادههایی که بر روی آن ارزیابی میشود، مهم است. این موضوع منجر به یک برآورد مغرضانه و بیش از حد خوش بینانه از عملکرد مدل میشود. نسبتهای تقسیم متداول برای تقسیم مجموعه دادهها 70:30، 80:20 یا 90:10 هستند، که در آن بخش بزرگتر برای آموزش و بخش کوچکتر برای اعتبارسنجی استفاده میشود.
چندین تکنیک برای تقسیم دادهها وجود دارد:
- نمونهگیری تصادفی Random: نقاط داده به طور تصادفی به مجموعه آموزشی یا اعتبارسنجی اختصاص داده میشوند و توزیع کلی داده را حفظ میکنند.
- نمونهگیری طبقهای Stratified sampling: نقاط داده به مجموعه آموزشی یا اعتبارسنجی اختصاص داده میشوند و در عین حال توزیع کلاس در هر دو زیر مجموعه حفظ میشود و اطمینان حاصل میشود که هر کلاس به خوبی نمایش داده میشود.
- اعتبار سنجی متقاطع K-fold: مجموعه داده به k زیرمجموعه با اندازه مساوی تقسیم میشود، و مدل k بار آموزش و اعتبارسنجی میشود، از هر زیر مجموعه به عنوان مجموعه اعتبار سنجی یک بار و زیر مجموعههای باقی مانده برای آموزش استفاده میشود. عملکرد نهایی در تکرار k به طور میانگین محاسبه میشود.
– تقویت داده
تقویت دادهها تکنیکی است که برای تولید نمونههای آموزشی جدید با اعمال تبدیلهای مختلف بر روی تصاویر و دادههای اصلی استفاده میشود. این فرآیند با افزایش تنوع دادههای آموزشی به بهبود قابلیتهای تعمیم مدل کمک میکند و مدل را در برابر تغییرات دادههای ورودی قویتر میکند. تکنیکهای رایج افزایش دادهها شامل چرخش، مقیاسبندی، چرخش و لرزش رنگ است. همه آن تکنیکها بدون تغییر محتوای زیربنایی تصاویر، تنوع را ایجاد میکنند.

– رسیدگی به عدم تعادل کلاس(Class imbalance)
عدم تعادل کلاس(Class imbalance) میتواند منجر به عملکرد مغرضانه مدل شود، که در آن مدل در کلاس اکثریت عملکرد خوبی دارد اما در کلاس اقلیت ضعیف است. پرداختن به عدم تعادل کلاس برای دستیابی به عملکرد مدل دقیق و قابل اعتماد بسیار مهم است. استراتژیهای مدیریت عدم تعادل کلاس شامل نمونهگیری مجدد است که شامل نمونهبرداری بیش از حد از طبقه اقلیت، کمنمونهسازی طبقه اکثریت یا ترکیبی از هر دو است. تکنیکهای تولید دادههای مصنوعی، مانند تکنیک نمونهبرداری بیش از حد اقلیت مصنوعی (SMOTE) نیز میتواند مورد استفاده قرار گیرد. علاوه بر این، تنظیم فرآیند یادگیری مدل، به عنوان مثال، از طریق وزن دهی کلاس، میتواند به کاهش اثرات عدم تعادل کلاس کمک کند.
محکها و مقایسه مدلها
یک ارزیابی کامل باید شامل معیارهای سنجش و عملکرد برای مقایسه مدلهای مختلف یادگیری ماشین باشد:
– اهمیت محکزدن(benchmarking)
بنچمارک برای مقایسه مدلها استفاده میشود زیرا یک روش استاندارد و عینی برای ارزیابی عملکرد آنها ارائه میدهد و توسعهدهندگان را قادر میسازد تا مناسبترین مدل را برای یک کار یا برنامه خاص شناسایی کنند. با مقایسه مدلها بر روی مجموعه دادههای رایج و معیارهای ارزیابی، بنچمارک کردن تصمیمگیری آگاهانه را تسهیل میکند و بهبود مستمر در توسعه مدل بینایی کامپیوتری را ارتقا میدهد.
– دیتاستهای عمومی محبوب برای محک زدن
مجموعه دادههای عمومی محبوب برای محکزدن مدلهای بینایی رایانه وظایف مختلفی مانند طبقهبندی تصویر، تشخیص اشیاء و تقسیمبندی را پوشش میدهد. برخی از مجموعه دادههای پرکاربرد در این حوزه عبارتند از:
- ImageNet: مجموعه دادهای در مقیاس بزرگ که حاوی میلیونها تصویر برچسبگذاری شده در هزاران کلاس است که در درجه اول برای طبقهبندی تصاویر و انتقال وظایف یادگیری استفاده میشود.
- COCO (اشیاء مشترک در زمینه): MS COCO یک مجموعه داده پرطرفدار با تصاویر متنوع است که دارای چندین شیء در هر تصویر است که برای کارهای تشخیص اشیاء، بخشبندی و وظایف زیرنویس استفاده میشود.
- Pascal VOC (کلاسهای شیء بصری): این مجموعه داده مهم حاوی تصاویری با اشیاء مشروح متعلق به 20 کلاس است که برای طبقهبندی و تشخیص اشیاء استفاده میشود.
- MNIST (مؤسسه ملی استاندارد و فناوری اصلاح شده): مجموعه دادهای از ارقام دستنویس که معمولاً برای طبقهبندی تصویر و محکزدن در یادگیری ماشین استفاده میشود.
- CIFAR-10/100 (موسسه تحقیقات پیشرفته کانادا): دو مجموعه داده متشکل از 60000 تصویر برچسبدار، تقسیم شده به 10 یا 100 کلاس، که برای کارهای طبقهبندی تصاویر استفاده میشود.
- ADE20K: مجموعه دادهای با تصاویر حاشیهنویسی برای تجزیه صحنه، که برای آموزش مدلها برای وظایف تقسیمبندی معنایی استفاده میشود.
- Cityscapes: مجموعه دادهای حاوی صحنههای خیابان شهری با حاشیهنویسی در سطح پیکسل، که عمدتاً برای بخشبندی معنایی و تشخیص اشیاء در برنامههای رانندگی مستقل استفاده میشود.
- LFW (تصاویر برچسبدار در صحنه): مجموعه دادهای از تصاویر چهره جمع آوری شده از اینترنت که برای تشخیص چهره و کارهای تأیید استفاده میشود.
مقایسه معیارهای عملکرد
ارزیابی چندین مدل شامل مقایسه معیارهای عملکرد آنها (به عنوان مثال، Precision، Recall، امتیاز F1 و AUC) است که برای تعیین اینکه کدام مدل به بهترین وجه نیازهای خاص یک برنامه خاص را برآورده میکند انجام میشود. در زیر جدولی برای راهنمایی در مورد نحوه مقایسه معیارها وجود دارد:
| معیار | هدف | مقدار ایدهآل | اهمیت |
|---|---|---|---|
| Precision | پیشبینیهای مثبت را اصلاح میکند | بالا | زمانی که هزینههای مثبت کاذب زیاد است یا زمانی که به حداقل رساندن تشخیصهای کاذب مورد نظر است، بسیار مهم است. |
| Recall | همه موارد مثبت را شناسایی کنید | بالا | زمانی که از دست دادن موارد مثبت پرهزینه است یا زمانی که تشخیص همه موارد مثبت حیاتی است، ضروری است. |
| F1 Score | عملکرد متعادل | بالا | هنگامی که با مجموعه دادههای نامتعادل سروکار داریم یا زمانی که مثبت کاذب و منفی کاذب هزینههای متفاوتی دارند مفید است. |
| AUC | عملکرد طبقهبندی کلی | بالا | برای ارزیابی عملکرد مدل در آستانههای طبقهبندی مختلف و هنگام مقایسه مدلهای مختلف مهم است. |
نتیجه گیری
در این مقاله در سایت الکتروهایو، اهمیت ارزیابی مدل بینایی کامپیوتر و بررسی عملکرد آن را برجسته کردیم که معیارهای عملکرد ضروری، تکنیکهای ارزیابی، عوامل مجموعهای و شیوههای محک را پوشش میدهد. ارزیابی دقیق و مستمر برای پیشرفت و اصلاح مدلهای بینایی کامپیوتر حیاتی است. به عنوان یک دانشمند داده، درک این روشهای ارزیابی برای تصمیمگیری آگاهانه هنگام انتخاب و بهینهسازی مدلها برای مورد استفاده خاص شما کلیدی است. با استفاده از معیارهای عملکردی متعدد و در نظر گرفتن فاکتورهای مجموعه داده، میتوانید اطمینان حاصل کنید که مدلهای بینایی کامپیوتری شما به سطوح عملکرد مطلوب دست مییابند و به پیشرفت این زمینه دگرگونکننده کمک میکنند. مهم است که مدلهای خود را برای دستیابی به بهترین نتایج ممکن در برنامههای بینایی کامپیوتر خود تکرار و اصلاح کنید.