
زمان تخمینی مطالعه: 9 دقیقه
یادگیری با نظارت شده که به عنوان یادگیری ماشین نظارت شده نیز شناخته میشود، زیرمجموعهای از یادگیری ماشین و هوش مصنوعی است. مفهوم یادگیری تحت نظارت با استفاده از مجموعه دادههای برچسبگذاریشده برای آموزش الگوریتمهایی که دادهها را طبقهبندی یا نتایج را با دقت پیشبینی میکنند، تعریف میشود. این بدان معناست که دانشمندان داده، هر نقطه داده در مجموعه آموزشی را با برچسب صحیح (مثلاً «گربه» یا «سگ») علامتگذاری کردهاند تا الگوریتم بتواند نحوه پیشبینی نتایج برای دادههای پیشبینی نشده را بیاموزد و اشیاء را در دادههای تصویر جدید بهطور دقیق شناسایی کند.
همانطور که دادههای ورودی به مدل وارد میشود، مدل یادگیری با نظارت وزن آن را تا زمانی تنظیم میکند که مدل به طور مناسب برازش شود، که به عنوان بخشی از فرآیند اعتبار سنجی متقابل رخ میدهد. یادگیری تحت نظارت کمک میکند تا انواع مشکلات دنیای واقعی را در مقیاس کوچک و بزرگ بتوانیم حل کنیم، این مشکلات میتواند طبقهبندی هرزنامهها در یک پوشه جداگانه از صندوق پیام ورودی باشد. از Supervised Learning میتوان برای ساخت مدلهای یادگیری ماشینی بسیار دقیق استفاده کرد.
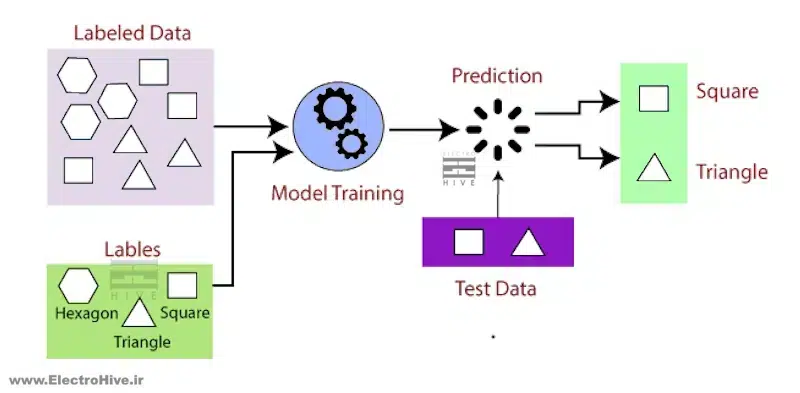
نحوه عملکرد یادگیری با نظارت
یادگیری با نظارت از یک مجموعه آموزشی برای آموزش مدلها برای به دست آوردن خروجی مطلوب استفاده میکند. این مجموعه داده آموزشی شامل ورودیها و خروجیهای صحیح است که به مدل اجازه میدهد در طول زمان یاد بگیرد. این الگوریتم دقت خود را از طریق تابع ضرر(loss function) اندازهگیری میکند، تا زمانی که خطا به اندازه کافی به حداقل برسد، مراحل تنظیم را انجام میدهد. یادگیری تحت نظارت را میتوان در حالت کلی به دو دسته کلی زیر تقسیم کرد:
- طبقهبندیClassification: از یک الگوریتم برای تخصیص دقیق دادههای تست(Test Data) به دستههای خاص استفاده میکند. موجودیتهای خاصی را در مجموعه داده شناسایی میکند و تلاش میکند تا در مورد اینکه چگونه آن موجودیتها باید برچسبگذاری یا تعریف شوند، نتیجهگیری کند. الگوریتمهای طبقهبندی رایج، طبقهبندیکنندههای خطی، ماشینهای بردار پشتیبان (SVM)، درختهای تصمیمگیری، k-نزدیکترین همسایه و جنگل تصادفی هستند که در زیر با جزئیات بیشتر توضیح داده شدهاند.
- رگرسیونRegression: رگرسیون نوعی یادگیری با نظارت است که در آن الگوریتمها از دادهها برای پیشبینی مقادیر پیوسته مانند فروش، حقوق، وزن یا دما یاد میگیرند. مثلا: مجموعه دادهای حاوی ویژگیهای خانه مانند اندازه زمین، تعداد اتاق خواب، تعداد حمام، محله و قیمت خانه است. یک الگوریتم رگرسیون را در این مورد میتوان آموزش داد تا رابطه بین ویژگیها و قیمت خانه را بیاموزد.
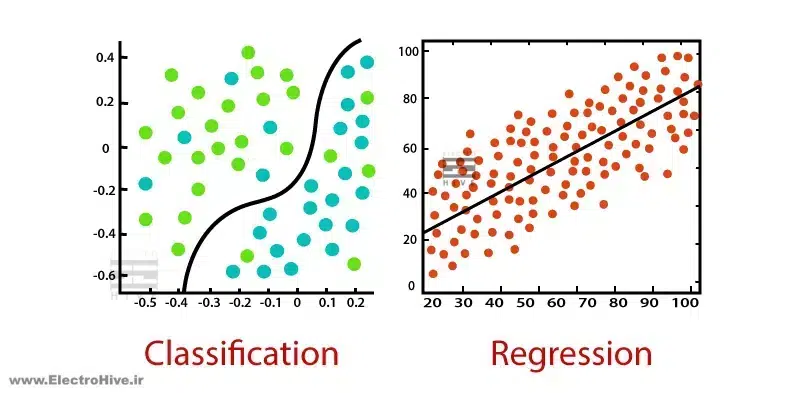
الگوریتمهای یادگیری با نظارت
الگوریتمها و تکنیکهای محاسباتی مختلفی در فرآیندهای یادگیری تحت نظارت استفاده میشوند. در زیر توضیحات مختصری درباره برخی از متداولترین روشهای یادگیری که معمولاً با استفاده از برنامههایی مانند R یا Python محاسبه میشوند، آورده شده است:
- شبکههای عصبی: شبکههای عصبی که عمدتاً برای الگوریتمهای یادگیری عمیق استفاده میشوند، دادههای آموزشی را با تقلید از اتصال مغز انسان از طریق لایههایی از گرهها پردازش میکنند. هر گره از ورودیها، وزنها، یک Bias (یا آستانه) و یک خروجی تشکیل شده است. اگر آن مقدار خروجی از یک آستانه معین فراتر رود، گره را “Fire” یا فعال میکند و دادهها را به لایه بعدی شبکه ارسال میکند. شبکههای عصبی این تابع نگاشت را از طریق یادگیری با نظارت، تنظیم بر اساس تابع از دست دادن(Loss Function) بوسیله فرآیند گرادیان نزولی، یاد میگیرند. زمانی که تابع هزینه نزدیک به صفر است، میتوانیم به دقت مدل برای به دست آوردن پاسخ صحیح اطمینان داشته باشیم.
- بیز ساده Naive bayes: روش بیز ساده رویکرد طبقهبندی است که اصل استقلال شرطی طبقاتی از قضیه بیز را اتخاذ میکند. این بدان معناست که وجود یک ویژگی بر وجود ویژگی دیگر در احتمال یک نتیجه معین تأثیر نمیگذارد و هر پیشبینی کننده تأثیر یکسانی بر آن نتیجه دارد. سه نوع طبقهبندی کننده نیوی بیز وجود دارد: چند جملهای بیز ساده، برنولی بیز ساده و گاوسی بیز شاده. این تکنیک در درجه اول در طبقهبندی متن، شناسایی هرزنامه و سیستمهای توصیه استفاده میشود.
- رگرسیون خطی: رگرسیون خطی برای شناسایی رابطه بین یک متغیر وابسته و یک یا چند متغیر مستقل استفاده میشود و معمولاً برای پیشبینی نتایج آینده مورد استفاده قرار میگیرد. زمانی که تنها یک متغیر مستقل و یک متغیر وابسته وجود داشته باشد، به آن رگرسیون خطی ساده میگویند. با افزایش تعداد متغیرهای مستقل، به آن رگرسیون خطی چندگانه میگویند. برای هر نوع رگرسیون خطی، به دنبال ترسیم خطی با بهترین برازش است که از طریق روش حداقل مربعات محاسبه میشود. با این حال، بر خلاف سایر مدلهای رگرسیون، این خط زمانی که بر روی یک نمودار رسم میشود مستقیم است.
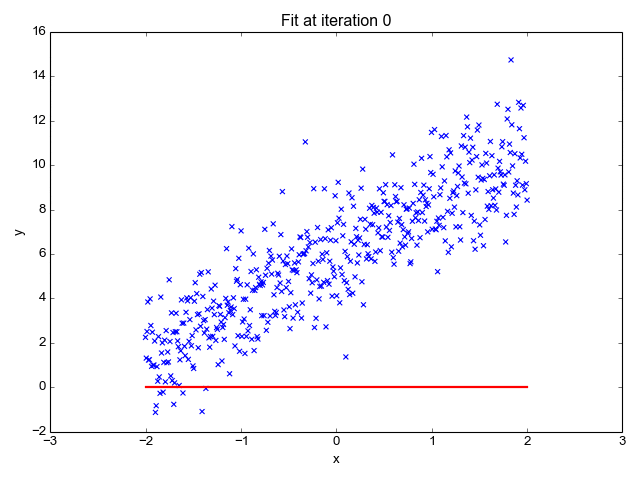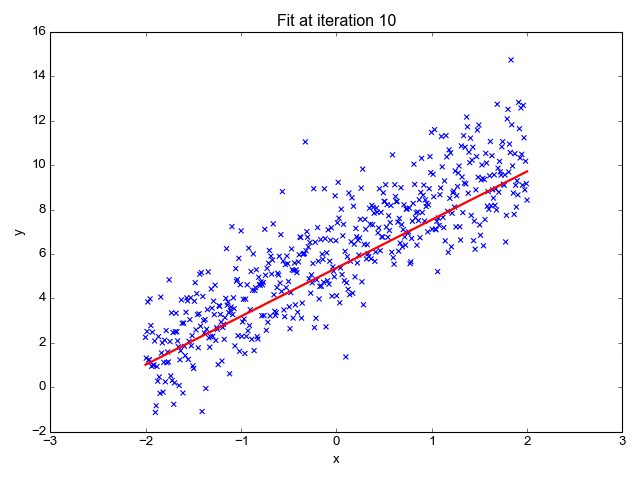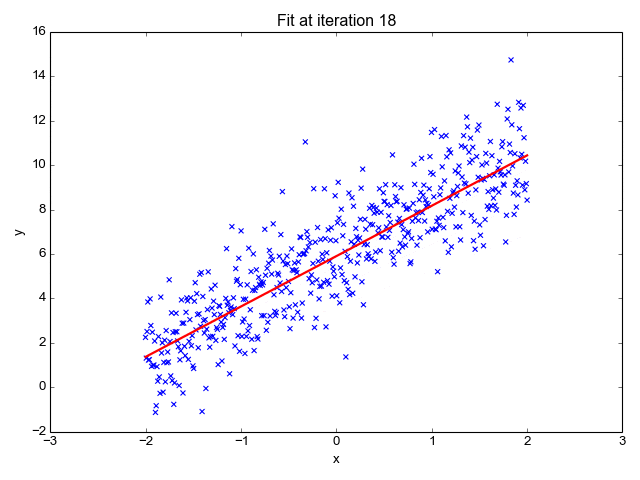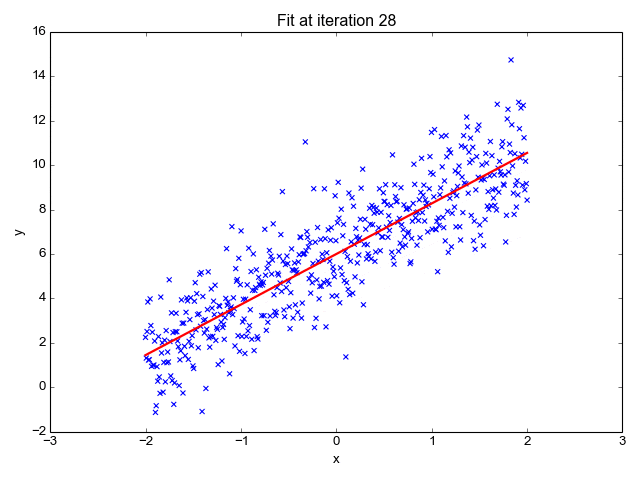
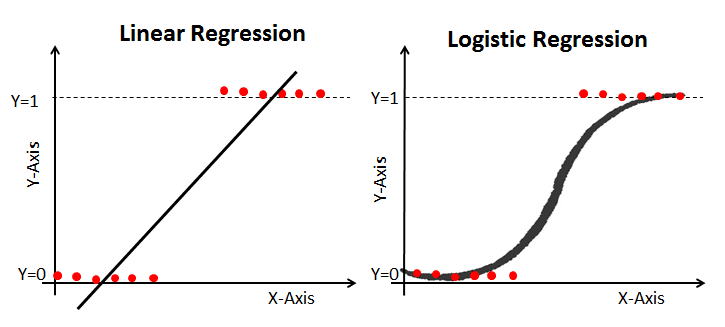
- رگرسیون لجستیک Logistic regression: در حالی که رگرسیون خطی زمانی اعمال میشود که متغیرهای وابسته پیوسته هستند، رگرسیون لجستیک زمانی انتخاب میشود که متغیر وابسته دارای طبقهبندی باشد، به این معنی که آنها خروجیهای باینری دارند، مانند “درست” و “نادرست” یا “بله” و “خیر”. در حالی که هر دو مدل رگرسیون به دنبال درک روابط بین ورودی دادهها هستند، رگرسیون لجستیک عمدتا برای حل مشکلات طبقهبندی باینری، مانند شناسایی هرزنامه استفاده میشود.
- ماشینهای بردار پشتیبان (SVM): ماشین بردار پشتیبان یک مدل یادگیری با نظارت محبوب است که توسط ولادیمیر واپنیک توسعه یافته است و برای طبقهبندی دادهها و رگرسیون استفاده میشود. گفته میشود، معمولاً برای مسائل طبقهبندی استفاده میشود، و یک ابرصفحه ایجاد میکند که فاصله بین دو کلاس از نقاط داده در حداکثر آن باشد. این ابرصفحه به عنوان مرز تصمیم شناخته میشود که کلاسهای نقاط داده (مثلاً پرتقال در مقابل سیب) را در دو طرف صفحه از هم جدا میکند.
- K-نزدیکترین همسایه: الگوریتم K-nearest همسایه که با نام الگوریتم KNN نیز شناخته میشود، یک الگوریتم ناپارامتریک است که نقاط داده را بر اساس نزدیکی و ارتباط آنها با سایر دادههای موجود طبقهبندی میکند. این الگوریتم فرض میکند که نقاط داده مشابه را میتوان در نزدیکی یکدیگر یافت. در نتیجه، به دنبال محاسبه فاصله بین نقاط داده، معمولاً از طریق فاصله اقلیدسی است، و سپس یک دسته را بر اساس پرتکرارترین دسته یا میانگین اختصاص میدهد. سهولت استفاده و زمان محاسبه کم آن را به الگوریتم مورد علاقه دانشمندان داده تبدیل میکند، اما با افزایش مجموعه داده آزمایشی، زمان پردازش طولانیتر میشود و جذابیت آن برای کارهای طبقهبندی کمتر میشود. KNN معمولاً برای موتورهای توصیه و شناسایی تصویر استفاده میشود.
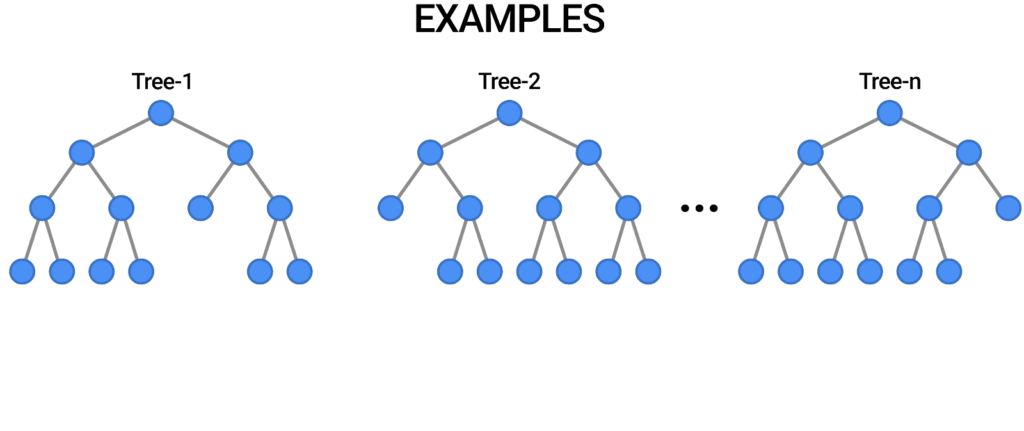
- جنگل تصادفی Random forest: جنگل تصادفی یکی دیگر از الگوریتمهای یادگیری تحت نظارت انعطافپذیر است که برای اهداف طبقهبندی و رگرسیون استفاده میشود. “جنگل” به مجموعهای از درختهای تصمیمگیری نامرتبط اشاره میکند که سپس برای کاهش واریانس و ایجاد پیشبینیهای دادههای دقیقتر، با هم ادغام میشوند.
نمونه کاربردهای یادگیری با نظارت
از مدلهای یادگیری تحت نظارت میتوان برای ساخت و پیشبرد تعدادی از برنامههای کاربردی تجاری استفاده کرد، از جمله موارد زیر:
- تشخیص تصویر و اشیا: الگوریتمهای یادگیری با نظارت را میتوان برای مکانیابی، جداسازی و دستهبندی اشیاء خارج از فیلمها یا تصاویر مورد استفاده قرار داد و در صورت استفاده از تکنیکهای بینایی کامپیوتری و تجزیه و تحلیل تصویر، آنها را مفید میسازد.
- تجزیه و تحلیل پیشبینیکننده Predictive analytics: یک مورد استفاده گسترده برای مدلهای یادگیری تحت نظارت، ایجاد سیستمهای تحلیل پیشبینیکننده برای ارائه بینش عمیق به نقاط مختلف دادههای تجاری است. این کاربرد به شرکتها و سازمانها اجازه میدهد تا نتایج خاصی را بر اساس یک متغیر خروجی معین پیشبینی کنند.
- تجزیه و تحلیل احساسات مشتری: با استفاده از الگوریتمهای یادگیری ماشینی با ناظر، سازمانها میتوانند اطلاعات مهمی را از حجم زیادی از دادهها در مورد زمینه، احساسات و قصد مشتری با دخالت بسیار کمی استخراج و طبقهبندی کنند. این کار میتواند در هنگام به دست آوردن درک بهتری از تعاملات مشتری بسیار مفید باشد و میتواند برای بهبود تلاشهای تعامل با برند استفاده شود.
- تشخیص هرزنامه: تشخیص هرزنامه نمونه دیگری از مدل یادگیری تحت نظارت است. با استفاده از الگوریتمهای طبقهبندی با نظارت، سازمانها میتوانند پایگاههای اطلاعاتی را برای تشخیص الگوها یا ناهنجاریها در دادههای جدید آموزش دهند تا مکاتبات هرزنامه و غیرمرتبط با هرزنامه را به طور مؤثر سازماندهی کنند.
چالشهای یادگیری تحت نظارت
اگرچه یادگیری با نظارت میتواند مزایایی مانند بینش عمیق دادهها و اتوماسیون بهبودیافته را به کسبوکارها ارائه دهد، در ساختن مدلهای یادگیری نظارت شده پایدار، چالشهایی وجود دارد. برخی از این چالشها به شرح زیر است:
- مدلهای یادگیری با نظارت میتوانند به سطوح خاصی از تخصص برای ساختار دقیق نیاز داشته باشند.
- آموزش مدلهای یادگیری تحت نظارت میتواند بسیار زمان بر باشد.
- مجموعه دادهها میتوانند احتمال خطای انسانی بیشتری داشته باشند و در نتیجه الگوریتمها اشتباه یاد بگیرند.
- برخلاف مدلهای یادگیری بدون نظارت، یادگیری با نظارت نمیتواند به تنهایی دادهها را خوشهبندی یا طبقهبندی کند.