
زمان تخمینی مطالعه: 9 دقیقه
حاشیهنویسی داده به الگوریتمهای یادگیری ماشین اجازه میدهد تا اطلاعات را درک و تفسیر کنند. حاشیهنویسیها برچسبهایی هستند که دادهها را شناسایی و طبقهبندی میکنند یا قطعات مختلف اطلاعات را با یکدیگر مرتبط میکنند. الگوریتمهای هوش مصنوعی از آنها به عنوان حقایق پایه برای تنظیم وزن خود استفاده میکنند. برچسبها وابسته به وظیفه متفاوت هستند و میتوانند بیشتر به عنوان حاشیهنویسی تصویر یا حاشیهنویسی متن طبقهبندی شوند. حاشیهنویسی متن برای درک الگوریتمهای یادگیری ماشین، معنی را با اطلاعات متنی مرتبط میکند. آنها برچسبهایی تولید میکنند که به الگوریتمهای یادگیری ماشین اجازه میدهند متن را به شکلی شبیه انسان تفسیر کنند. این فرآیند شامل طبقهبندی بلوکهای متن، برچسبگذاری عناصر متنی برای حاشیهنویسی و درک معنایی، یا مرتبط کردن هدف با دادههای مکالمه است. هر یک از این روشها، مدلهای یادگیری ماشین را برای موارد استفاده عملی مختلف آموزش میدهند.
حاشیهنویسی متن Text Annotation چیست؟
هدف فرآیند حاشیهنویسی متن(Text Annotation)، تولید معنا از متن با برجسته کردن ویژگیهای کلیدی مانند بخشهایی از گفتار، پیوندهای معنایی، یا احساس کلی یا هدف سند است. هر وظیفه حاشیهنویسی، متن را به طور متفاوتی برچسبگذاری میکند و برای موارد استفاده متفاوت استفاده میشود. یک برنامه تحلیل احساسات نیازمند طبقهبندی بلوکهای متن در یک دسته احساسات است. اسناد متنی و حاشیهنویسیهای مرتبط با آنها (برچسبها) برای آموزش مدلهای یادگیری ماشین برای درک متن استفاده میشوند. در این ساختار مدل یاد میگیرد که حاشیهنویسی را با پیکره ورودی ارائه شده مرتبط کند و سپس همان ارتباط را با دادههای دیده نشده تکرار میکند.
چالشهای اصلی حاشیهنویسی متن
فرآیند حاشیهنویسی ساده است، اما چالشهای خاصی را به همراه دارد. چالشها بر کیفیت حاشیهنویسی و عملکرد مدل تاثیرگذاری گذاشته و یا آن را مختل میکند. این موضوع شامل:
- وقت گیر است: مجموعه متن میتواند گسترده باشد، و برچسب زدن دستی کل مجموعه داده زمان و منابع زیادی را صرف میکند. برخی از ابزارهای حاشیهنویسی با کمک هوش مصنوعی روند را سرعت میبخشند، اما عملکرد آنها به دلیل ماهیت ساختار نیافته دادهها متفاوت است و مشارکت انسان یک ضرورت است.
- طبقهبندی غلط هدف: رمزگشایی احساسات و مقاصد در اسناد متنی ممکن است دشوار باشد. مجموعه دادههای دنیای واقعی مملو از ابهاماتی مانند طعنه است که حاشیهنویسی قصد یا احساسات کاربر را دشوار میکند.
- تغییرات متن: متن شکلی از بیان است و حتی با ساختارها یا عبارات مختلف میتواند معنای یکسانی داشته باشد. یک مجموعه داده با کیفیت باید شامل همه این تغییرات باشد و دارای حاشیهنویسی باشد. تنوع، پیچیدگی دادههای جمع آوری شده و حاشیهنویسی شده را افزایش میدهد.
انواع مختلف روشهای Text Annotation
متن را میتوان با استفاده از روشهای مختلف برچسبگذاری کرد، و هر روش حاشیهنویسی مشکل متفاوتی را هدف قرار میدهد. در اینجا برخی از برجستهترین روشهای حاشیهنویسی متن مورد استفاده در حوزه یادگیری ماشین آورده شده است.
- طبقهبندی متن: اسناد متنی را میتوان به دستههای مختلف بسته به وظیفه در دست طبقهبندی کرد. فرآیند طبقهبندی هر سند متنی را با یک برچسب مرتبط میکند و این ارتباط بعداً برای آموزش الگوریتمهای یادگیری ماشین استفاده میشود. میتوان آن را به صورت زیر دستهبندی کرد:
- حاشیهنویسی احساسات: متنهایی مانند نظرات مشتریان و پستهای رسانههای اجتماعی معمولا احساسات متفاوتی را بیان میکنند. چنین تکههای متنی را میتوان به عنوان “شاد”، “غمگین”، “عصبانی” یا “هیجان زده” بر اساس دانه بندی کلاس بر اساس الزامات کار مورد نیاز طبقهبندی کرد. حاشیهنویسی احساسات طبقهبندی احساسات مورد استفاده در کسب و کار خرده فروشی برای تجزیه و تحلیل بررسی محصول را آموزش میدهد.
- مدلسازی موضوع: اسناد متنی را نیز میتوان بر اساس اطلاعاتی که در خود دارند و موضوعی که نشان میدهند طبقهبندی کرد. به عنوان مثال، متون آموزشی را میتوان در موضوعاتی مانند “ریاضیات”، “فیزیک”، “زیست شناسی” و غیره طبقهبندی کرد. علاوه بر این، حاشیهنویسیهای مدلسازی موضوع میتواند به چت باتها کمک کند تا زمینه سریع در LLM را درک کند.
- حاشیهنویسی هرزنامه: میتوانیم مجموعههای متنی از ایمیلها یا پلتفرمهای پیامرسان را بهعنوان «هرزنامه» یا «ایمن» حاشیهنویسی کنیم. این یادداشتها طبقهبندیکنندههای هرزنامه را برای برنامههای امنیتی آموزش میدهند.
- برچسبگذاری موجودیت: متن زبان طبیعی شامل عناصر مختلفی است که به مفهوم متن معنا میبخشد. برچسبگذاری موجودیت این عناصر را در کلاسهای مربوطه برچسبگذاری میکند. موجودیتهای برچسبگذاری شده به مشکل موجود بستگی دارد. درک معناشناسی متن و ساختار دستوری آن مستلزم برچسبگذاری بخشهایی از گفتار (POS) مانند اسمها، افعال و صفتها است.

- پیوند موجودیت: پیوند موجودیت مشابه برچسبگذاری موجودیت است زیرا عناصر فردی موجود در متن را نیز شناسایی میکند. با این حال، هدف آن پیوند دادن موجودیت فعلی به یک پایگاه دانش خارجی برای ایجاد زمینه گستردهتر است. به عنوان مثال، در متن، “Elon Musk بنیانگذار SpaceX است”، پیوند نهاد “Elon Musk” را به اطلاعات مربوطه در پایگاه داده پیوند میدهد تا بفهمد که چه کسی برای درک بهتر متن است.
- حاشیهنویسی قصد(Intent): چت باتها دستورات متنی را بر اساس قصد کاربر تشخیص میدهند و سعی میکنند پاسخ مناسبی را ایجاد کنند. حاشیهنویسی قصد، متن را به دستههای هدف مانند درخواست، سؤال، فرمان و غیره طبقهبندی میکند. اینها به رباتهای چت اجازه میدهند مکالمه را هدایت کنند و به سؤالات پاسخ دهند یا اقداماتی را انجام دهند.
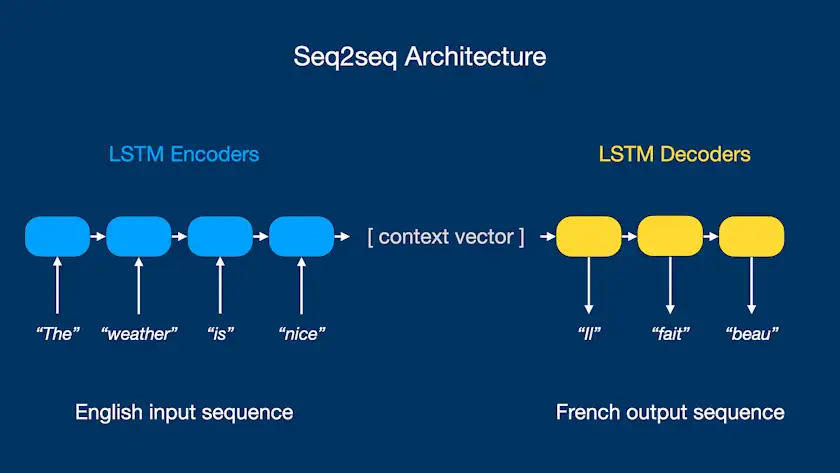
- حاشیه نویسی دنباله به دنباله: مدلهای مدرن دنباله به دنباله، یک توالی متن را بر روی دیگری ترسیم میکنند. یک مثال محبوب، مدلهای خلاصهسازی متن است که یک متن بزرگ را به عنوان ورودی میپذیرد و یک دنباله فشرده بهطور قابل توجهی را خروجی میکند. مورد دیگر ترجمه زبان انسانی است که در آن خروجی دنبالهای مشابه با ورودی است اما به زبانی متفاوت.
کاربردهای حاشیهنویسی متن
تکنیکهای حاشیهنویسی متن که در بالا مورد بحث قرار گرفت، کاربردهای مختلف پردازش زبان طبیعی (NLP) را تقویت میکند. کاربردهای حاشیه نویسی متن دارای موارد استفاده متنوعی در حوزههای مختلف هستند. آنها اتوماسیون کارهای وقتگیر را ممکن میکنند و کار دستی را با جریانهای کاری کامپیوتری جایگزین مینمایند. بیایید چند مورد استفاده کلیدی از حاشیهنویسی متن را در ادامه مورد بحث قرار دهیم.
- شناسایی موجودیت نامگذاری شده (NER): NER یک کاربرد محبوب در NLP است که موجودیتهای موجود در متن را شناسایی میکند. موجودیتها میتوانند شامل نام، مکان، تاریخ و زمان باشند. این موجودیتها به رایانهها اجازه میدهند متن را تجزیه و تحلیل کنند و گردشهای کاری خودکار را اجرا کنند. به عنوان مثال، مدلهای NER میتوانند مکان، تاریخ و زمان ذکر شده در ایمیلهای شرکت را تشخیص دهند و یادآورهای خودکار را برای یک جلسه تنظیم کنند. همچنین میتوان از NER برای استخراج موجودیتهای مفید از متنهای بزرگ استفاده کرد. پزشکان میتوانند از آن برای بازیابی دارو و نام بیماران از پروندههای پزشکی بزرگ استفاده کنند تا بفهمند چه چیزی برای چه بیمار تجویز شده است. علاوه بر این، مدلهای NER نیز از پنجرههای زمینه برای درک هویت موجودیت استفاده میکنند. به عنوان مثال، در جمله “پاریس یک مکان زیبا است”، متن مربوطه به تشخیص اینکه “پاریس” یک مکان است و نه یک شخص کمک میکند.
- چت باتهای پشتیبانی مشتری: چت باتها به سرعت نیاز به تعامل و پشتیبانی کارآمد با مشتری را برآورده میکنند. چت باتهای مدرن از ترکیبی از طبقهبندی، برچسبگذاری نهاد و شناسایی هدف برای شکستن درخواست مشتری استفاده میکنند. تکنیکهای ذکر شده به آنها کمک میکند تا مفاهیم را درک کنند و به درستی پاسخ دهند. آنها میتوانند موجودیتها را از متن تشخیص دهند تا بفهمند که شخص به کدام محصول یا دسته اشاره میکند. علاوه بر این، آنها میتوانند هدف کاربر را شناسایی کنند، خواه آنها در مورد یک محصول پرس و جو کنند، درخواست بازپرداخت یا ثبت شکایت کنند. طبقهبندی قصد به چت بات کمک میکند تا پاسخهای مناسب را ایجاد کند و اقدامات لازم را انجام دهد. علاوه بر این، آنها همچنین از تجزیه و تحلیل احساسات برای تشخیص عصبانیت یا ناراحتی مشتری استفاده میکنند و پرس و جو را به یک انسان هدایت میکنند.
- تجزیه و تحلیل مشتری: مشتریان اغلب نظرات محصول را در رسانههای اجتماعی یا از طریق یک پورتال مشخص از شرکت ارسال میکنند. تجزیه و تحلیل احساسات به کسب و کارها این امکان را میدهد که این نظرات را به مثبت و منفی تفکیک کنند بدون اینکه آنها را به صورت دستی بررسی کنند. بررسیهای منفی بیشتر برای هر گونه الگوی تکرار شونده یا محصولی که نیاز به تعمیر دارد مشاهده میشود. تجزیه و تحلیل احساسات به سازمانها کمک میکند تا کیفیت محصول و رضایت مشتری را بهبود بخشند.
- تفکیک مقاله Article Segregation: تکنیکهایی مانند مدلسازی موضوع و شناسایی موجودیت، مقالات را به موضوعات مختلف تفکیک میکند. این امر بهویژه برای پخشکنندگان خبری برجسته است، که مقالات خبری را به موضوعاتی مانند سیاست، مسائل اجتماعی، اخبار جهانی و غیره تفکیک میکنند. پلتفرمهای رسانههای اجتماعی نیز از تکنیکهای مشابهی برای دستهبندی محتوا به موضوعات استفاده میکنند. اسناد طبقهبندی شده بیشتر برای سخنان مشوق عداوت و تنفر یا موضوعات مورد بررسی قرار میگیرند. این تحلیلها برای توسعه ویژگیهای جدید برای جذب کاربران جدید استفاده میشود.