
زمان تخمینی مطالعه: 14 دقیقه
هدف تشخیص سوگیری در بینایی کامپیوتر یافتن و حذف سوگیریهای(Bias) ناعادلانه است که میتواند منجر به خروجیهای نادرست یا تبعیض آمیز از سیستمهای بینایی کامپیوتر شود. بینایی کامپیوتر به ویژه در سالهای اخیر به نتایج قابل توجهی دستیافته است و در اکثر وظایف از انسانها بهتر عمل کرده است. با این حال، سیستمهای CV به شدت به دادههایی که روی آنها آموزش دیدهاند وابسته هستند و میتوانند یاد بگیرند که تعصب در چنین دادههایی را تقویت کنند. بنابراین، شناسایی سوگیری و کاهش تعصب از اهمیت بالایی در این الگوریتمها برخوردار است. این مقاله سایت الکتروهایو، انواع کلیدی سوگیری در بینایی کامپیوتر، تکنیکهای مورد استفاده برای شناسایی و کاهش آنها، و ابزارهای ضروری و بهترین شیوهها برای ساختن سیستمهای بینایی کامپیوتر منصفانه را بررسی میکند.
انواع و منشاء تشخیص سوگیری در بینایی کامپیوتر
تشخیص سوگیری(Bias Detection) در هوش مصنوعی (AI) به طور کلی به شناسایی خطاها یا تعصبات سیستماتیک در مدلهای هوش مصنوعی اشاره دارد که سوگیریهای اجتماعی را تقویت کرده و منجر به نتایج ناعادلانه یا تبعیض آمیز میشود. در حالی که سوگیری در سیستمهای هوش مصنوعی یک حوزه تحقیقاتی به خوبی تثبیت شده است، حوزه بینایی کامپیوتر جانبدارانه آنچنان مورد توجه قرار نگرفته است. این امر با توجه به حجم گسترده دادههای بصری مورد استفاده در یادگیری ماشین امروزی و اتکای شدید تکنیکهای یادگیری عمیق مدرن به این دادهها برای کارهایی مانند تشخیص اشیاء و طبقهبندی تصویر مربوط میشود. این سوگیریها در دادههای بینایی کامپیوتر میتوانند در مورد راههایی ظاهر شوند که منجر به تبعیض بالقوه در برنامههای کاربردی دنیای واقعی مانند تبلیغات هدفمند یا اجرای قانون شود. درک انواع سوگیری که میتواند مدلهای CV را خراب کند، اولین گام به سمت تشخیص و کاهش سوگیری است. توجه به این نکته مهم است که دستهبندی سوگیری دادههای بصری میتواند بین منابع متفاوت باشد.
در این بخش رایجترین انواع سوگیری در مجموعه دادههای بصری برای وظایف بینایی کامپیوتر فهرست میشود.
– سوگیری انتخاب Selection Bias
سوگیری انتخاب (که به آن سوگیری نمونه نیز گفته میشود) زمانی رخ میدهد که نحوه انتخاب تصاویر برای مجموعه داده، عدم تعادلهایی را ایجاد میکند که اطلاعات دنیای واقعی را منعکس نمیکند. این بدان معنی است که مجموعه داده ممکن است گروهها یا موقعیتهای خاصی را بیش از حد یا کمتر نشان دهد که منجر به یک مدل بالقوه ناعادلانه شود. هنگام جمعآوری مجموعه دادههای معیار مقیاس بزرگ، احتمال بیشتری وجود دارد که انواع خاصی از تصاویر انتخاب شوند، زیرا به تصاویر جمعآوریشده از منابع آنلاین در دسترس با سوگیریهای اجتماعی موجود یا روشهای پاکسازی و فیلتر کردن خودکار بستگی دارند. این امر درک چگونگی تشخیص تعصب نمونه در این مجموعه دادهها برای اطمینان از مدلهای منصفانهتر را ضروری میسازد. در اینجا چند نمونه هستند:
- Caltech101: تصاویر خودرو بیشتر از کناره گرفته شده است
- ImageNet: شامل اتومبیلهای مسابقهای بیشتری است.
بازنمایی کمتر از گروههای مختلف میتواند منجر به مدلهایی شود که افراد را بر اساس ویژگیهای محافظتشده مانند جنسیت یا قومیت به اشتباه طبقهبندی یا شناسایی نادرست میکنند و در نتیجه پیامدهای دنیای واقعی را به دنبال دارد. مطالعات نشان داد که نرخ خطا برای افراد تیره پوست میتواند 18 برابر بیشتر از افراد با پوست روشن در برخی از الگوریتمهای طبقهبندی جنسیتی تجاری باشد.
الگوریتمهای تشخیص چهره یکی از حوزههایی هستند که تحتتاثیر سوگیری نمونهگیری قرار میگیرند، زیرا بسته به دادههایی که روی آن آموزش دیدهاند، میتوانند نرخهای خطای متفاوتی ایجاد کنند. از این رو، چنین فناوری به مراقبت بسیار بیشتری نیاز دارد، به ویژه در برنامههای کاربردی مانند اجرای قانون. با این حال، شایان ذکر است که حتی اگر این عدم تعادل کلاس تأثیر قابلتوجهی دارد، آنها هر نابرابری را در عملکرد الگوریتمهای یادگیری ماشین توضیح نمیدهند. مثال دیگر، سیستمهای رانندگی خودکار است، زیرا جمعآوری مجموعه دادهای که هر صحنه و موقعیت ممکنی را که ممکن است خودرو با آن مواجه شود را توصیف کند، بسیار چالش برانگیز است.

– سوگیری کادربندی Framing Bias
سوگیری یا تعصب کادربندی به نحوه ثبت، ترکیب و ویرایش تصاویر در یک مجموعه داده بصری اشاره دارد که بر آنچه یک مدل بینایی کامپیوتر میآموزد تأثیر میگذارد. این سوگیری تأثیر عناصر بصری مانند زاویه، نور، برش و انتخابهای فنی مانند تقویت در طول جمعآوری تصویر را در بر میگیرد. نکته مهم این است که سوگیری کادربندی با سوگیری انتخاب متفاوت است، زیرا هر یک پیچش نیز خود را نشان میدهد. یکی از نمونههای سوگیری کادربندی، سوگیری ضبط است. تحقیقات نشان میدهد که نمایش افراد دارای اضافه وزن در تصاویر میتواند به طور قابل توجهی در محتوای بصری متفاوت باشد، به طوری که تصاویر بدون سر در مقایسه با تصاویر افرادی که اضافه وزن ندارند بسیار بیشتر است. این نوع تصاویر اغلب به مجموعه دادههای بزرگی که برای آموزش سیستمهای CV استفاده میشوند، مانند موتورهای جستجوی تصویر، راه پیدا میکنند. حتی برای ما، تصمیمات ما تحت تأثیر نحوه چارچوببندی برخی چیزها است زیرا این یک استراتژی بازاریابی است که به طور گسترده مورد استفاده قرار میگیرد. به عنوان مثال، یک مشتری یک بطری شیر با برچسب بدون چربی 80٪ را به یک بطری با 20٪ چربی ترجیح میدهد، حتی اگر محتوای آنها یکی باشد.

سوگیری کادربندی در جستجوی تصویر میتواند منجر به نتایجی شود که کلیشههای مضر را حتی بدون عبارات جستجوی صریح تداوم میبخشد. به عنوان مثال، جستجو برای یک حرفه عمومی مانند “کارگر ساختمانی” ممکن است منجر به عدم تعادل جنسیتی در نمایش شود. صرف نظر از اینکه خود الگوریتم بایاس است یا به سادگی سوگیریهای موجود را منعکس میکند، نتیجه نمایشهای منفی را تقویت میکند. این امر بر اهمیت تشخیص سوگیری در بینایی کامپیوتر تاکید میکند.
– سوگیری برچسب Label Bias
دادههای برچسبگذاریشده برای یادگیری با نظارت ضروری هستند، و کیفیت آن برچسبها برای هر مدل یادگیری ماشین، بهویژه در بینایی کامپیوتر، حیاتی است. خطاها و سوگیریهای برچسبگذاری به دلیل پیچیدگی و حجم آنها میتوانند در مجموعه دادههای امروزی بسیار رایج باشند و تشخیص سوگیری در آن مجموعه دادهها را به چالش میکشند. ما میتوانیم سوگیری برچسب را به عنوان تفاوت بین برچسبهای اختصاص داده شده به تصاویر و حقیقت اصلی آنها تعریف کنیم، این شامل اشتباهات یا ناسازگاری در نحوه طبقهبندی داده های بصری است. این موضوع میتواند زمانی اتفاق بیفتد که برچسبها محتوای واقعی تصویر را منعکس نمیکنند، یا زمانی که دستهبندی برچسبها خود مبهم یا گمراه کننده هستند.

با این وجود، این امر به ویژه با تصاویر مربوط به انسان مشکل ساز میشود. برای مثال، سوگیری برچسب میتواند شامل سوگیری مجموعهای منفی باشد که در آن برچسبها نمیتوانند تنوع کامل یک دسته را نشان دهند. برای مقابله با چالشهایی مانند تعصبنژادی، استفاده از ویژگیهای بصری خاص یا ویژگیهای قابل اندازهگیری (مانند بازتاب پوست) اغلب دقیقتر از مقولههای ذهنی مانند نژاد است. یک الگوریتم طبقهبندی که بر روی برچسبهای بایاس آموزش داده شده است، احتمالاً هنگام استفاده در دادههای جدید، این سوگیریها را تقویت میکند. این امر اهمیت تشخیص سوگیری را در اوایل چرخه حیات دادههای بصری برجسته میکند.
چرخه حیات دادههای بصری
درک چگونگی تشخیص سوگیری در منبع آن بسیار مهم است. چرخه حیات محتوای بصری یک چارچوب مفید برای این ارائه میدهد. این موضوع نشان میدهد که سوگیری میتواند در چند مرحله معرفی یا تقویت شود.
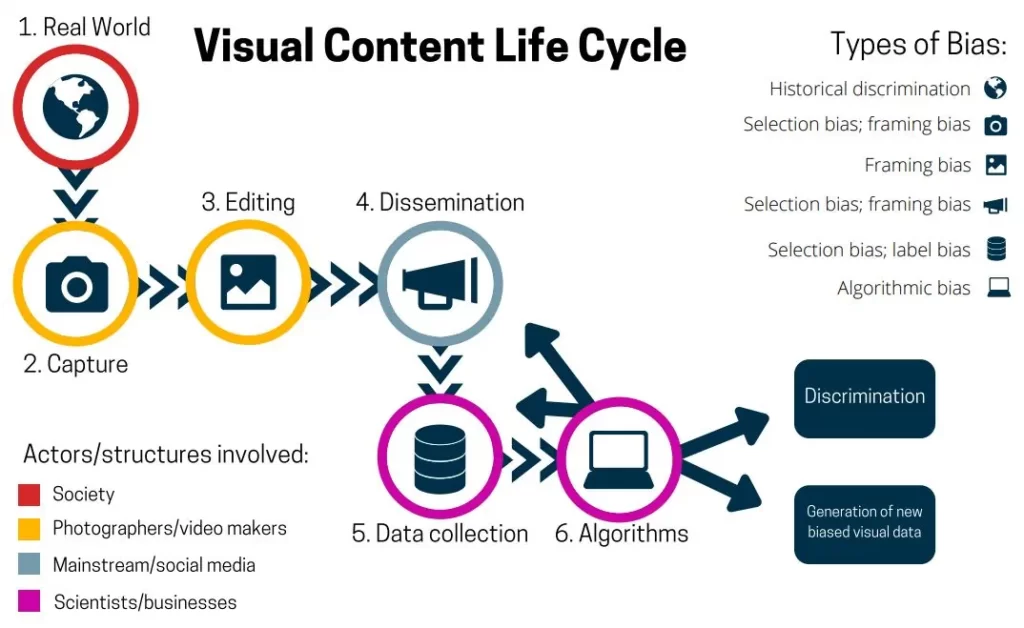
چرخه حیات پتانسیل سوگیریهایی مانند سوگیری عکسبرداری را نشان میدهد (زوایای دوربین بر ادراک تأثیر میگذارد). با توجه به فرآیندهای نشان داده شده در تصویر، سوگیریهای دیگری نیز میتوانند در طول چرخه حیات محتوای بصری رخ دهند. این شامل سوگیری در دسترس بودن (با استفاده از دادههای به راحتی در دسترس)، یا سوگیری اتوماسیون (اتوماتیک کردن فرآیند برچسبگذاری و/یا جمعآوری) است. در این مقاله ما، انواع اصلی بایاس را ذکر کردیم، زیرا سایر سوگیریها معمولاً زیر مجموعه این موارد هستند. این سوگیریها اغلب بر هم اثر میگذارند و همپوشانی ایجاد میکنند، زیرا انواع مختلف سوگیری میتوانند همزمان رخ دهند و تشخیص سوگیری را حتی مهمتر میکنند.
تکنیکهای تشخیص سوگیری در بینایی کامپیوتر
تشخیص بایاس در مجموعه دادههای بصری گامی حیاتی در جهت ایجاد سیستمهای بینایی کامپیوتر منصفانه و قابل اعتماد است. محققان طیف وسیعی از تکنیکها را برای کشف این سوگیریها توسعه دادهاند و از ایجاد مدلهای عادلانهتر اطمینان میدهند. بیایید چند رویکرد کلیدی در این حوزه را بررسی کنیم.
- کاهش به دادههای جدولی Reduction To Tabular Data: این دسته از روشها بر روی ویژگیها و برچسبهای مرتبط با تصاویر تمرکز میکنند. با استخراج این اطلاعات و نمایش آن در قالب جدولی، محققان میتوانند روشهای تشخیص سوگیری به خوبی تثبیت شده برای مجموعه دادههای جدولی را اعمال کنند. ویژگیهای استخراجشده برای این نمایش جدولی میتواند مستقیماً از تصاویر با استفاده از ابزارهای تشخیص و تشخیص تصویر یا از ابردادههای موجود مانند زیرنویسها یا ترکیبی از هر دو باشد. تجزیه و تحلیل بیشتر داده های جدولی استخراج شده راههای مختلفی را برای ارزیابی سوگیری احتمالی را نشان میدهد.
- نمایشهای بصری متعصبانه: در حالی که کاهش دادههای تصویر به دادههای جدولی میتواند ارزشمند باشد، گاهی اوقات تجزیه و تحلیل نمایشهای تصویر بینشهای منحصربهفردی را در مورد سوگیری ارائه میدهد. این روشها بر نمایشهای با ابعاد پایینتر از تصاویر تمرکز میکنند، که نشان میدهد چگونه یک مدل یادگیری ماشین ممکن است آنها را ببیند و گروهبندی کند. ابن نحوه نمایش برای تشخیص سوگیری بر تجزیه و تحلیل فواصل و روابط هندسی تصاویر در فضایی با ابعاد کمتر متکی هستند. روشهای این دسته شامل روشهای مبتنی بر فاصله و روشهای دیگر است. برای استفاده از این روشها، محققان مطالعه میکنند که چگونه مدلهای از پیش آموزشدیده تصاویر را در فضایی با ابعاد پایینتر نشان میدهند، و فاصله بین آن نمایشها را برای تشخیص سوگیری در مجموعه دادههای بصری محاسبه میکنند.
- تشخیص سوگیری بین مجموعهای از دادهها: این روشها مجموعه دادههای مختلف را با هم مقایسه میکنند و «امضاهایی» را که سوگیریها را آشکار میکنند، جستجو میکنند. این مفهوم “امضا” از این واقعیت ناشی میشود که محققان باتجربه اغلب میتوانند تشخیص دهند که یک تصویر از کدام مجموعه داده معیار با دقت خوبی میآید. این امضاها (سوگیریها) الگوها یا ویژگیهای منحصر به فردی در یک مجموعه داده هستند که معمولاً بر توانایی یک مدل برای تعمیم به خوبی بر روی دادههای نادیده جدید تأثیر میگذارند. تعمیم دادههای متقابل یکی از روشهای مورد استفاده در این دسته است که آزمایش میکند یک مدل چقدر به زیرمجموعهای از دادههایی که در آن آموزش ندیده تعمیم مییابد.
- سایر روشها: برخی از روشها تحت هیچ یک از دستهبندیهای ذکر شده تا کنون قرار نمیگیرند. مدلهای یادگیری عمیق ذاتاً روشهای جعبه سیاه هستند، و حتی اگر آن مدلها بیشترین موفقیت را در وظایف بینایی داشتند، توضیحپذیری آنها هنوز ضعیف ارزیابی میشود.
راهکارهای کاهش سوگیری در بینایی کامپیوتر
با تکیه بر تکنیکهای تشخیص سوگیری در بینایی کامپیوتر که قبلاً بررسی کردیم، محققان مجموعه دادههای معیار محبوب را تجزیه و تحلیل میکنند تا انواع سوگیری موجود در آنها را شناسایی کنند و از ایجاد مجموعههای داده منصفانهتر مطمئن شوند. از آنجایی که سوگیری مجموعه داده منجر به سوگیری الگوریتمی میشود، استراتژیهای کاهش معمولاً بر بهترین شیوهها برای ایجاد مجموعه داده و نمونهبرداری تمرکز میکنند. این رویکرد به ما امکان میدهد تا یک فرآیند جمعآوری دادههای بصری آگاه از تعصب داشته باشیم تا سوگیری را از پایه مدلهای بینایی کامپیوتر به حداقل برسانیم. این بخش به تشریح تکنیکهای کاهش عملی سوگیری میپردازد که بر سه حوزه تمرکزی تقسیم میشوند:
- ایجاد مجموعه داده:
- تلاش برای نمایندگی متعادل: با استفاده از مثالهای متنوع از نظر جنسیت، رنگ پوست، سن و سایر ویژگیهای محافظتشده، میتوان با سوگیری انتخاب مبارزه کرد. نمونهبرداری بیش از حد از گروههایی که کمتر نشان داده شدهاند یا تنظیم دقیق ترکیب دادهها میتواند این تعادل را تقویت کند. به عنوان مثال، یک مجموعه داده شامل فقط بزرگسالان جوان را میتوان با افزودن تصاویر سالمندان متعادل کرد.
- برچسبها را به طور انتقادی در نظر بگیرید: مراقب باشید که برچسبها چگونه میتوانند سوگیری را معرفی کنند و در صورت امکان، رویکردهای برچسبگذاری دقیقتری را در نظر بگیرید. تحمیل مقولاتی مانند دستهبندیهای نژادی بیش از حد ساده میتواند خود نوعی سوگیری باشد. بهعنوان مثال، بهجای برچسب «آسیایی»، در صورت لزوم، شناسههای منطقهای یا فرهنگی خاصتری را وارد کنید.
- چالشهای جمعسپاری(Crowdsourcing): حاشیهنویسهای جمعسپاری معمولاً ناسازگاری دارند، زیرا حاشیهنویسهای فردی میتوانند سوگیریهای بالقوهای داشته باشند. بنابراین، اگر از حاشیهنویسی جمع سپاری استفاده میکنید، مطمئن شوید که مکانیسمهای کنترل کیفیت را اجرا کنید. به عنوان مثال، به حاشیهنویسان دستورالعملها و آموزشهای روشنی در مورد سوگیریهای احتمالی ارائه دهید.
- فرآیندهای جمع آوری:
- نمایش محیطهای متنوع: برای جلوگیری از تعصب در کادربندی، مطمئن شوید که تنوع در نور، زوایای دوربین، پسزمینه و نمایش سوژه را ثبت کنید. معرفی دادههای مصنوعی میتواند تنوع بیشتری به تنظیمات تصاویر بدهد. این امر از تطبیق بیش از حد مدلها با زمینهها یا شرایط نوری خاص جلوگیری میکند و امکان اندازه نمونه مناسب را فراهم میکند. به عنوان مثال، عکسهایی که هم در داخل و هم در فضای باز گرفته شدهاند.
- مراقب حذف باشید: تأثیر بالقوه حذف کلاسهای شیء خاص بر عملکرد مدل را در نظر بگیرید. این همچنین بر نمونههای منفی تأثیر میگذارد، حذف کلاسهای شیء عمومی («افراد»، «تختها») میتواند تعادل را تغییر دهد.
- ملاحظات گستردهتر:
- گسترش دامنه جغرافیایی: سوگیری جغرافیایی یکی از انواع سوگیریهای نمونه است. این سوگیری در طیف گستردهای از مجموعه دادهها وجود دارد که ایالات متحده محور یا اروپا محور هستند. بنابراین، گنجاندن تصاویر از مناطق مختلف برای مبارزه با این سوگیری مهم است. به عنوان مثال، جمع آوری تصاویر از کشورهای مختلف در چندین قاره.
- پیچیدگی هویت را تصدیق کنید: برچسبهای جنسیتی باینری گاهی اوقات نمیتوانند هویت جنسیتی را منعکس کنند و به رویکردهای متفاوتی نیاز دارند. بنابراین، نمایش فراگیر در مجموعه دادهها میتواند مفید واقع شود.
نتیجه گیری
این مقاله مقدمهای پایهای برای درک تشخیص سوگیری در بینایی کامپیوتر، پوشش انواع سوگیری، روشهای تشخیص و استراتژیهای کاهش ارائه میکند. همانطور که در بخشهای قبلی اشاره شد، سوگیری در طول چرخه زندگی دادههای بصری فراگیر است. تحقیقات بیشتر باید نمایشهای غنیتری از دادههای بصری، رابطه بین تعصب و هندسه فضای پنهان، و تشخیص سوگیری در ویدیو را بررسی کند. برای کاهش سوگیری، ما به شیوههای جمعآوری داده عادلانهتر و آگاهی بیشتر از سوگیریها در آن مجموعه دادهها نیاز داریم.