
زمان تخمینی مطالعه: 4 دقیقه
هوش مصنوعی (AI) هر روزی که طی میشود به تکامل خود ادامه میدهد و با گسترش آن مدلهایی را میطلبد که قادر به مدیریت مجموعه دادههای گسترده و ارائه بینش دقیق هستند. برای برآوردن این نیازها، محققان NVIDIA و MIT اخیراً در یک همکاری مشترک یک مدل زبان بصری (VLM) با نام هوش مصنوعی VILA را معرفی کردهاند. این مدل جدید هوش مصنوعی به دلیل توانایی استثنایی خود در استدلال در بین تصاویر متعدد، محصولی کاملا متمایز است. علاوه بر این، این مدل یادگیری درون زمینهای(in-context) را تسهیل کرده و همچنین ویدیوها را درک میکند که پیشرفت قابل توجهی در سیستمهای هوش مصنوعی چندوجهی(multimodal AI) میباشد.
تکامل مدلهای هوش مصنوعی
در حوزه تحقیقات هوش مصنوعی که زمینهای بسیار پویا است، یادگیری و انطباق مداوم از اهمیت بالایی برخوردار است. چالش فراموشی فاجعهآمیز، که در آن مدلها برای حفظ دانش قبلی در حین یادگیری وظایف جدید تلاش میکنند، راهحلهای نوآورانهای را برانگیخته است. تکنیکهایی مانند تثبیت وزن الاستیک (EWC) و تجربه مجدد در کاهش این چالش بسیار مهم بوده است. علاوه بر این، معماریهای شبکه عصبی ماژولار و رویکردهای فرا یادگیری، راههای منحصر به فردی را برای افزایش سازگاری و کارایی ارائه میدهند.
ظهور هوش مصنوعی VILA
محققان NVIDIA و MIT یک مدل زبان بصری جدید با نام هوش مصنوعی VILA را که برای رفع محدودیتهای مدلهای هوش مصنوعی طراحی شده است، رونمایی کردند. رویکرد متمایز VILA بر هم ترازی تعبیهشده مؤثر و معماریهای شبکه عصبی پویا تأکید دارد. مدل هوش مصنوعی VILA با استفاده از ترکیبی از اجسام بهم پیوسته و تنظیم دقیق تحت نظارت مشترک، قابلیتهای یادگیری بصری و متنی را افزایش میدهد. به این ترتیب، نمایش عملکرد قوی در وظایف مختلف را تضمین میکند.
افزایش همترازی بصری و متنی
برای بهینهسازی همترازی بصری و متنی، محققان از یک چارچوب پیشآموزشی جامع، با استفاده از مجموعههای داده در مقیاس بزرگ مانند Coyo-700m استفاده کردند. توسعه دهندگان استراتژیهای مختلف آموزش دیده را تست کردهاند و تکنیکهایی مانند Visual Instruction Tuning را در مدل گنجاندهاند. در نتیجه، مدل هوش مصنوعی VILA توانسته است بهبود دقت قابل توجهی را در وظایف پاسخگویی بصری از خود نشان دهد.
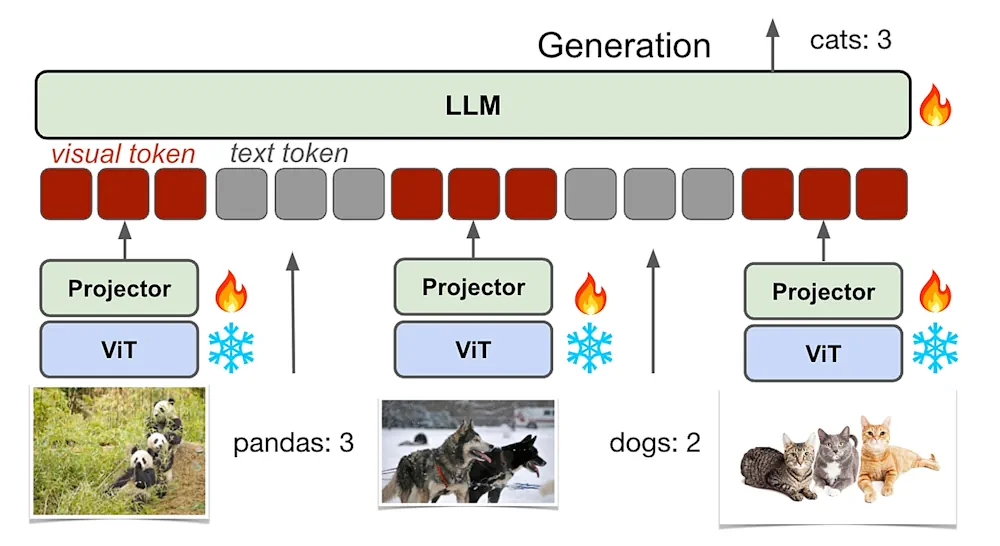
روشهای موجود مانند Llava از تنظیم دستورالعمل بصری برای گسترش LLM با ورودیهای بصری استفاده میکنند، اما فاقد مکاشفه عمیق فرآیند پیشآموزشی زبان بصری هستند، جایی که مدل یاد میگیرد مدلسازی مشترک را در هر دو روش انجام دهد.
کارایی و سازگاری
معیارهای عملکرد مدل VILA به خوبی نمایش دهنده دستاوردهای قابل توجهی در دقت در معیارهایی مانند OKVQA و TextVQA است. قابل ذکر است، مدل VILA حفظ دانش استثنایی را از خود نشان میدهد و تا 90 درصد از اطلاعات آموختهشده قبلی را در حین سازگاری با وظایف جدید حفظ میکند. این کاهش در فراموشی فاجعهآمیز(catastrophic forgetting) بر سازگاری و کارایی VILA در مدیریت چالشهای در حال تکامل هوش مصنوعی تأکید میکند.
نتیجه گیری
معرفی مدل VILA نشان دهنده پیشرفت قابل توجهی در زمینه هوش مصنوعی چندوجهی(multimodal AI) است که چارچوبی امیدوارکننده برای توسعه مدل زبان بصری(VLM) را ارائه میکند. رویکرد نوآورانه آن برای پیشآموزش و تراز کردن، اهمیت طراحی مدل جامع را در دستیابی به عملکرد برتر در برنامههای مختلف برجسته میکند. همانطور که هوش مصنوعی همچنان در بخشهای مختلف در حال گسترش نفوذ خود است، قابلیتهای VILA نویدبخش نوآوریهای متحول کننده است که مطمئناً راه را برای سیستمهای هوش مصنوعی کارآمدتر و سازگارتر هموار خواهد کرد.