
زمان تخمینی مطالعه: 20 دقیقه
توانایی ماشینها برای یادگیری و سازگاری به سرعت در حال تغییر جهان اطراف ما است. همین چند دهه پیش، تشخیص چهره یا ترجمه خودکار کارهایی غیر ممکن برای یک ماشین بود. این موارد در حال حاضر برنامههای معمولی هستند و پیشرفتهای هیجان انگیزی با سرعت فزایندهای در حال ظهور هستند. Deep Learning، زیرشاخه پیشرفته هوش مصنوعی، در قلب این انقلاب قرار دارد. علاوه بر این، داستان یادگیری عمیق به یک آرزوی همیشگی برای القای هوشمندی ماشینها اشاره دارد. این مقاله عملکرد درونی و پتانسیل گسترده یادگیری ژرف را توضیح خواهد داد.
Deep Learning چیست؟
یادگیری عمیق روشی برای آموزش شبکههای عصبی برای انجام وظایف با حداقل دخالت انسان است. الگوریتمهای یادگیری عمیق بر اساس ساختار و عملکرد مغز بیولوژیکی، با استفاده از لایههای به هم پیوسته نورونهای مصنوعی برای پردازش و یادگیری از دادهها، مدلسازی میشوند.
یادگیری ماشینی در مقابل یادگیری عمیق
Deep Learning یک زیرنوع از یادگیری ماشین و بخشی از هوش مصنوعی (AI) است. یادگیری ماشینی اصطلاح گستردهتری است که به فرآیند یادگیری کامپیوترها از دادهها بدون برنامهنویسی صریح برای انجام یک کار اشاره دارد. الگوریتمهای یادگیری ماشین به جای تکیه بر دستورالعملهای از پیش تعیینشده، الگوهای درون دادهها را شناسایی میکنند و در صورت ارائه اطلاعات جدید، پیشبینیهایی را در مورد نتیجه مورد نظر انجام میدهند.
مدل های یادگیری عمیق از شبکه پیچیدهای از گرههای به هم پیوسته برای پردازش مقادیر زیادی داده استفاده میکنند. آنها به طور کلی قدرتمندتر از مدلهای یادگیری ماشینی هستند و میتوانند کارهای پیچیدهتری را انجام دهند. در اینجا جدولی برای مقایسه تفاوتها ارائه شده است:
| یادگیری ماشین | یادگیری عمیق | |
| ساختار الگوریتم | الگوریتمهای سادهتر مانند رگرسیون خطی و درخت تصمیم | شبکههای عصبی مصنوعی پیچیده و چند لایه |
| نیازمندی داده | میتواند با مجموعه دادههای کوچکتر کار کند | برای آموزش موثر به حجم زیادی از داده نیاز دارد |
| دخالت انسان | برای مهندسی ویژگی و تنظیم مدل به مداخله انسانی نیاز دارد | استخراج ویژگیها را خودکار میکند و از دادههای خام یاد میگیرد |
| کاربرد | برای کارهایی مانند رگرسیون، طبقهبندی و خوشهبندی استفاده میشود. | در کارهای پیچیده مانند تشخیص تصویر و گفتار، پردازش زبان طبیعی، و سیستمهای خودمختار عالی است |
مرور کوتاهی از تاریخچه یادگیری عمیق
ظهور شبکههای عصبی از زمان معرفی اولین کامپیوترهای دیجیتال تا به امروز را در بر میگیرد.
– وعده و چالشهای اولیه (1943-1979)
زمینه ژئوپلیتیکی جنگ سرد بین ایالات متحده و اتحاد جماهیر شوروی عمیقاً مراحل اولیه شبکههای عصبی را شکل داد. توسعه هوش مصنوعی یک ابتکار استراتژیک برای کسب برتری تکنولوژیکی بود. این مسابقه تسلیحاتی سرمایهگذاری و استعداد زیادی را به هوش مصنوعی وارد کرد و زمینه را برای برنامههای غیرنظامی بعدی فراهم کرد. اواخر دهه 1970 و اوایل دهه 1980 نیز اولین زمستان هوش مصنوعی بود. در طول این مدت، خوشبینی اولیه در مورد پتانسیل هوش مصنوعی با عقب نشینی کاهش یافت. این فناوری انتظارات بالای پیشگامان اولیه را برآورده نکرد و به طور فزایندهای دریافتند که دستیابی به هوش مصنوعی واقعی بیش از آنچه در ابتدا تصور میشد گریزان بود. جدول زمانی این دوره به شکل زیر است:
- وارن مک کالوچ و والتر پیتس پایه و اساس را با اولین مدل شبکه عصبی پایه گذاری کردند.
- Alexey Ivakhnenko و Valentin Lapa پیشگام الگوریتمهای یادگیری عمیق هستند.
- دهه 1970 اولین زمستان هوش مصنوعی شور و شوق تحقیقات را کاهش میدهد.
- کونیهیکو فوکوشیما شبکه Neocognitron، یک شبکه عصبی کانولوشنال را توسعه داد.
– تجدید حیات و اصلاح (1980-1999)
محققان هوش مصنوعی ادعاهای جسورانهای در مورد قابلیتهای خلاقیت خود داشتند. هنگامی که وظایف وعده داده شده مانند بازی شطرنج در سطح استاد بزرگ یا ترجمه بیعیب و نقص زبانها از بین رفت، ناامیدی و شک جایگزین هیجان شد. یکی از دلایل اصلی عدم ارائه سیستمهای هوش مصنوعی اولیه این بود که در دهه 1980، قدرت محاسباتی چیزی شبیه به امروز نبود. الگوریتمهای اولیه فاقد قدرت مقابله با مسائل پیچیده به طور موثر بودند. علاوه بر این، دادههای مورد نیاز برای آموزش آن الگوریتمها کمیاب بود و مانع پیشرفت بیشتر میشد. حتی با وجود پیشرفتها، همیشه نحوه استفاده از هوش مصنوعی برای مزایای ملموس مشخص نبود. سیستمهای اولیه اغلب در وظایف خاص بدون قابلیت تجاری گسترده برتری داشتند. با کاهش علاقه و کندی کلی در پیشرفت، بودجه برای تحقیقات هوش مصنوعی بار دیگر خشک شد و استعدادها شروع به ترک این حوزه کردند.جدول زمانی رویدادهای این دوره:
- Yann LeCun پس انتشار عملی را به نمایش میگذارد و علاقه به این حوزه را زنده میکند.
- دومین زمستان هوش مصنوعی تحقیقات در حوزه شبکهعصبی را در بر میگیرد .
- Cortes و Vapnik ماشین بردار پشتیبانی (SVM) را توسعه دادند.
- LSTM، یک معماری شبکه عصبی بازگشتی قدرتمند، اختراع شد.
– پیشرفت و تکیه به قله (1999-2020)
در قرن بیست و یکم، تمرکز هوش مصنوعی بر روی نیازهای اینترنت و حمایت از اقتصاد دیجیتال در حال ظهور تغییر کرده است. توسعه سریع سخت افزار کامپیوتر همچنین آموزش و استقرار مدلهای پیچیده هوش مصنوعی را تقویت کرد و زمینه را به سمت قابلیتهای بیسابقهای سوق داد. رونق فعلی هوش مصنوعی بر اساس درسهای آموخته شده از زمستانهای گذشته ساخته شده است. محققان بر روی کاربردهای عملی، استفاده از سخت افزار قدرتمند و مقادیر انبوه داده و کاوش در رویکردهای جدید مانند یادگیری عمیق تمرکز میکنند. جدول زمانی رویدادهای این دوره:
- رایانههای سریعتر و پردازندههای گرافیکی، قدرت محاسباتی شبکههای عصبی را افزایش میدهند.
- دهه 2000 مشکل گرادیان ناپدید شونده(The vanishing gradient problem) با پیش آموزش لایه به لایه و LSTM حل شد.
- دهه 2010 پردازندههای گرافیکی آموزش کارآمد شبکههای عصبی کانولوشن را امکانپذیر میسازند.
- AlexNet و Google Brain’s Cat Experiment مهارت یادگیری عمیق را به نمایش گذاشتند.
- ایان گودفلو شبکههای عصبی متخاصم مولد (GAN) را معرفی کرد.
- AlphaGo از DeepMind، قهرمان جهان Go را شکست داد (Lee Sedol) و نقطه عطف مهمی در هوش مصنوعی بازی بود.
- AlphaZero قدرت یادگیری عمیق را با تسلط بر چندین بازی بدون دانش قبلی از قوانین، از جمله Go، شطرنج و شوگی نشان میدهد.
- پیشرفتهای مداوم در مدلهای زبان بزرگ (LLM) مانند ChatGPT و Bard، قابلیتهای رو به رشد یادگیری عمیق در پردازش زبان طبیعی را نشان میدهد.
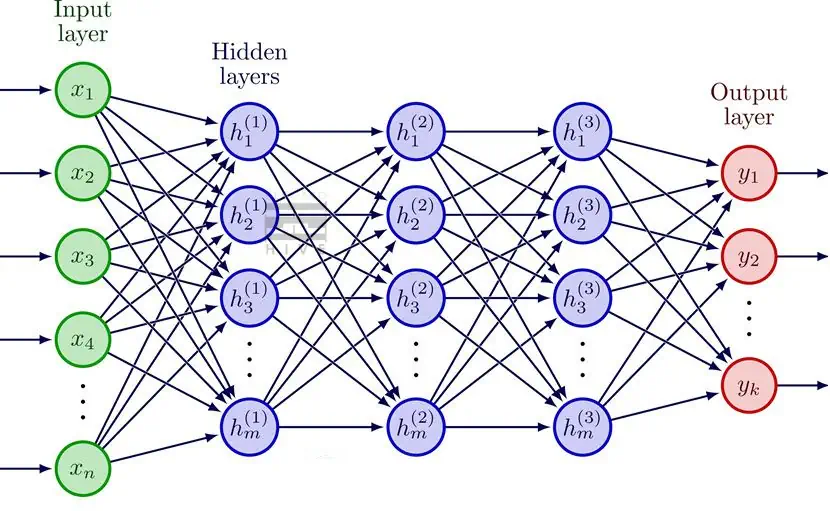
مولفههای یادگیری عمیق
در یادگیری عمیق، شبکههای عصبی از چندین لایه شامل ورودی، لایه پنهان و خروجی تشکیل شدهاند. هر لایه شامل گرههای به هم پیوسته یا نورونهای مصنوعی است که اطلاعات را پردازش کرده و به لایه بعدی منتقل میکند. شبکه پارامترهای خود را از طریق پس انتشار تنظیم میکند تا تفاوت بین پیشبینیهای خود و نتایج واقعی در دادههای آموزشی را به حداقل برساند. در زیر خلاصهای از سه لایه اصلی موجود در یک شبکه عصبی یادگیری عمیق آورده شده است.
– لایه ورودی
لایه ورودی لایه ای است که دادههای ورودی را دریافت میکند. پردازش و انتقال دادهها به لایههای بعدی در شبکه عصبی را بر عهده میگیرد. یک شبکه عصبی عمیق شامل چندین گره است که مسئول ورود دادهها هستند. ساختار گره بسته به نوع داده ورودی متفاوت است.
– لایه پنهان
لایههای پنهان در سطوح مختلف پردازش اطلاعات را انجام میدهند و رفتار خود را با کسب اطلاعات جدید تطبیق میدهند. شبکههای Deep Learning لایههای پنهان زیادی را در خود جای میدهند و به آنها اجازه میدهند تا یک مشکل را از دیدگاههای مختلف بررسی کنند. به عنوان مثال، هنگامی که یک الگوریتم بینایی کامپیوتری Deep Learning با تصویری از یک حیوان نا آشنا مواجه میشود، آن را با پایگاه دادهای از حیوانات شناخته شده مقایسه میکند. این الگوریتم اشکال و اندازههای اصلی در تصویر مانند شکل چشمها و گوشها، اندازه و تعداد پاها را برای شناسایی الگوها بررسی میکند. وجود سم در حیوان نشان دهنده طبقهبندی بالقوه به عنوان گاو یا گوزن است. چشمهای گربه مانند ممکن است نشان دهنده گونهای از گربههای وحشی یا اهلی باشد. هر لایه پنهان ویژگیهای متمایز را پردازش میکند و هدف آنها در واقع دستهبندی صحیح ورودی است.
– لایه خروجی
لایه خروجی شامل گرههایی است که مسئول تولید خروجی داده نهایی هستند. مدلهای Deep Learning با طبقهبندی باینری پاسخهای «بله» یا «خیر» را تنها از طریق دو گره در لایه خروجی ارائه میکنند. برعکس، مدلهایی که طیف وسیعتری از کلاسهای پاسخ را ارائه میدهند، شامل گرههای بیشتری هستند.
یادگیری عمیق چگونه کار میکند؟
یادگیری عمیق مراحل بسیاری را طی میکند و همان فرآیند را از طریق تکرارهای متعدد تکرار میکند. یک شبکه عصبی ابتدا بر روی دادههای برچسبگذاری شده آموزش میبیند تا از نمونهها یاد بگیرد قبل از اینکه روی دادههای بدون برچسب پیشبینی انجام دهد. در اینجا مراحل یادگیری عمیق، از تغذیه دادهها داخل شبکه تا اصلاح پیشبینیهای آن وجود دارد:
- پیش پردازش دادهها: برخی از الگوریتمها فقط میتوانند دادههای ساخت یافته را پردازش کنند در حالی که برخی دیگر با دادههای بدون ساختار کار میکنند. در اینجا چند نمونه از وظایف پیش پردازش آورده شده است:
- حذف نویز یا ناهماهنگی در دادهها، که یک مشکل رایج هنگام کار با سیستمهای حسگر یا دادههای ثبت شده است.
- مقیاسبندی یا تنظیم مقادیر دادهها در محدوده استاندارد برای بهبود همگرایی مدل.
- رسیدگی به دادههای از دست رفته
- دادهها: دادههای ورودی در شبکه، مانند یک تصویر یا یک جمله را تغذیه کنید.
- استخراج ویژگی: هر لایه پنهان دادهها را تجزیه و تحلیل میکند و ویژگیهای پیچیدهتر را از مجموعه داده استخراج میکند.
- پیش بینی: لایه نهایی ویژگیهای استخراج شده را ترکیب میکند و یک پیشبینی را تشکیل میدهد.
- بررسی خطا: پیشبینی با پاسخ واقعی (برچسب) مقایسه میشود.
- پس انتشار: اگر پیشبینی اشتباه باشد، شبکه خطا را محاسبه کرده و از آن برای تنظیم اتصالات بین نورونها (وزنها) استفاده میکند. وزنها سهم هر ورودی را در خروجی کلی نورون کنترل میکنند. نورونهایی با اتصالات قویتر (وزنهای بالاتر) بر فعالیت لایه زیر تأثیر میگذارند.
- تکرار: این فرآیند با دادههای جدید مجدداً راه اندازی میشود و به طور مکرر درک شبکه از مشکل را اصلاح میکند و پیشبینیها را بهبود میبخشد.
نمونههای یادگیری عمیق
یادگیری عمیق موفقیت قابل توجهی در کاربردهای مختلف نشان داده است. توانایی آن در یادگیری خودکار نمایشهای سلسله مراتبی از دادهها، آن را به ابزاری قدرتمند برای حل مسائل پیچیده و دستیابی به سطوح بالایی از دقت در کارهایی تبدیل کرده است که زمانی برای یادگیری ماشین سنتی چالش برانگیز بودند. در زیر چند نمونه در سه زمینه محبوب یادگیری عمیق آورده شده است: بینایی کامپیوتر، پردازش زبان طبیعی (NLP)، و موتورهای توصیه.
– بینایی ماشین Computer Vision
- وسایل نقلیه خودمختار: وسایل نقلیه خودران از یادگیری عمیق برای شناسایی علائم جاده، عابران پیاده و موانع استفاده میکنند.
- سیستمهای دفاعی: تجزیه و تحلیل تصاویر ماهوارهای از Deep Learning برای شناسایی نقاط مورد نظر و ردیابی اشیاء در فواصل بسیار زیاد استفاده میکند.
- تعدیل محتوا و تحلیل تصویر: الگوریتمها بهطور خودکار محتوای نامناسب را از وبسایتها حذف میکنند، ویژگیهای چهره را تشخیص میدهند و جزئیاتی مانند لوگوی برند را از تصاویر استخراج میکنند.
– پردازش زبان طبیعی (NLP)
- رباتهای چت: الگوریتمهای NLP چتباتهای هوشمندی را فعال میکنند که در مکالمات شبه انسانی شرکت میکنند و خدمات مشتریان را ارائه میدهند.
- خلاصهسازی اسناد و هوش تجاری: یادگیری عمیق اطلاعات حیاتی را از اسناد استخراج میکند و دادههای تجاری را تجزیه و تحلیل میکند و امکان بازیابی دانش و تصمیمگیری آگاهانه را فراهم میکند.
- دستیاران مجازی: یادگیری عمیق دستیارهای مجازی مانند سیری و الکسا را تقویت میکند.
- تجزیه و تحلیل احساسات و بینش در رسانههای اجتماعی: نمایهسازی احساسات در پلتفرمهای رسانههای اجتماعی از مدلهای NLP برای درک افکار عمومی و پیگیری روندها استفاده میکند.
– موتورهای پیشنهادی
- توصیههای شخصی: یادگیری عمیق رفتار و ترجیحات کاربر را برای ارائه توصیههای شخصی در خرده فروشی، رسانه و سایر صنایع تجزیه و تحلیل میکند. به عنوان مثال، پلتفرمهایی مانند Netflix و Spotify از Deep Learning برای توصیه محتوا بر اساس رفتار کاربر استفاده میکنند.
- ایمنی صنعتی: کارخانهها یادگیری عمیق را برای شناسایی الگوهای تصادف و نزدیکی ناایمن بین افراد و ماشینها پیادهسازی میکنند.
الگوریتمهای یادگیری عمیق
هر الگوریتم یک روش گام به گام برای انجام یک کار خاص یا حل یک مشکل است. در یادگیری عمیق، الگوریتمها محاسبات پیچیدهای را انجام میدهند که دادهها را لایه به لایه پردازش میکند و الگوهای پیچیده را از طریق عملیات ریاضی استخراج میکند. یادگیری ژرف به جعبه ابزاری از الگوریتمها متکی است که هر کدام در وظایف خاصی عالی هستند. در زیر چندین الگوریتم Deep Learning شناخته شده وجود دارد که امروزه مورد استفاده قرار میگیرند.
– شبکههای عصبی کانولوشن (CNN)
CNN ها از چندین لایه کانولوشن برای استخراج ویژگی، لایههای ادغام برای کاهش ابعاد، و لایههای کاملا متصل برای پیشبینیهای نهایی استفاده میکنند. آنها در تشخیص تصویر، تشخیص اشیا و تجزیه و تحلیل ویدئویی عالی هستند و به طور موثر ویژگیها و الگوهای فضایی را در دادههای بصری شناسایی میکنند.
– شبکههای عصبی مکرر (RNN)
پردازش دادهها به صورت متوالی، یک عنصر در یک زمان، RNN ها زمینه و روابط درون یک توالی داده را ضبط میکنند. رویکرد ترتیبی آنها را برای مدیریت دادههای متوالی مانند متن و صدا موثر میکند. نقطه قوت آنها مدلسازی زبان، تولید متن، تحلیل احساسات و وظایف پیشبینی توالی است.
– شبکههای حافظه کوتاه مدت (LSTM)
شبکههای حافظه کوتاهمدت یا LSTM شکل پیشرفتهای از شبکههای عصبی بازگشتی (RNN) هستند. آنها برای مقابله با چالش حفظ اطلاعات در توالیهای طولانیتر، که RNN ها به دلیل محدودیتهای حافظه کوتاه مدت با آن دست و پنجه نرم میکنند، طراحی شدهاند. LSTM ها از سلولهای حافظه تخصصی استفاده میکنند که آنها را برای کارهایی که شامل دادههای متوالی مانند متن و صدا هستند بسیار موثر میکند. کاربردهای آنها از ترجمه و تشخیص گفتار گرفته تا تحلیل احساسات، پیشبینی سریهای زمانی و تولید موسیقی را شامل میشود.
– شبکههای متخاصم مولد (GAN)
شبکههای متخاصم مولد از دو شبکه عصبی مولد و ممیز تشکیل شدهاند. دو شبکه درگیر یک فرآیند رقابتی هستند: مولد(generator) دادههای مصنوعی ایجاد میکند، در حالی که متمایز کننده(discriminator) واقعی یا جعلی بودن دادههای تولید شده را ارزیابی میکند. از طریق تعامل و یادگیری مستمر، مولد خروجی خود را اصلاح میکند تا به طور فزایندهای قانع کننده شود، در حالی که تمایزکننده توانایی خود را برای تمایز بین دادههای واقعی و تولید شده بهبود میبخشد. این فرآیند آموزش خصمانه منجر به تولید محتوای مصنوعی با کیفیت بالا و واقعی میشود.
– پرسپترونهای چندلایه (MLP)
متشکل از لایههای متعدد نورونهای به هم پیوسته با جریان اطلاعات به جلو، MLPها همه کاره هستند و پیادهسازی آنها آسان است و به دلیل ساختار سادهشان، نقطه شروع خوبی برای Deep Learning است.MLP ها در تشخیص تصویر، وظایف طبقهبندی، تقریب تابع و مشکلات رگرسیون برتری دارند.
– نقشههای خودسازماندهی (SOM)
با استفاده از گرههای رقیب که دادههای ورودی را بر روی نقشهای با ابعاد پایین تطبیق میدهند و نمایش میدهند، SOMها به طور مؤثر کاهش ابعاد و تجسم دادهها را انجام میدهند و الگوها و روابط را در مجموعه دادههای پیچیده آشکار میکنند. تخصص آنها خوشهبندی دادهها، تشخیص ناهنجاری، تجزیه و تحلیل بازار و تجسم دادههای با ابعاد بالا است.
– رمزگذارهای خودکار
رمزگذارهای خودکار دادههای ورودی را به صورت فشرده نمایش میدهند. آنها با رمزگذاری دادهها در فضایی با ابعاد پایینتر و بازسازی آن به شکل اصلی به این امر دست مییابند. آنها در کارهای مختلف مانند فشردهسازی تصویر، کاهش ابعاد، تشخیص ناهنجاری و تمیز کردن دادهها عالی هستند.
چارچوبهای یادگیری عمیق
برای استفاده از مفاهیم Deep Learning شما مجبور نیستید از ابتدا یک شبکه عصبی بسازید. چارچوبها و کتابخانههایی وجود دارند که یادگیری عمیق را در دسترس قرار میدهند. علاوه بر این، بسیاری از این چارچوبها منبع باز هستند و میتوانند با رویکرد مبتنی بر کلاد و بدون سختافزار اختصاصی، از آنها استفاده کنند. در اینجا بهترین چارچوبهای یادگیری عمیق موجود است:
- TensorFlow:
- یادگیری ماشین منبع باز و چارچوب هوش مصنوعی.
- توسط تیم Google Brain توسعه یافته است.
- TensorFlow 2.0 در سال 2019 منتشر شد.
- پشتیبانی از زبانهای برنامهنویسی مختلف
- دارای ویژگی داخلی اجرای شبکه عصبی ابتداعی
- PyTorch
- یادگیری ماشین منبع باز و چارچوب شبکه عصبی
- توسعه یافته توسط آزمایشگاه تحقیقاتی هوش مصنوعی فیس بوک (FAIR).
- پشتیبانی از پایتون و سی پلاس پلاس
- محاسبات تسریع شده GPU
- تمایز خودکار با اتوگراد.
- دارای اجرای شبکه عصبی داخلی با torch.nn
- Keras
- Front-end سطح بالا برای TensorFlow
- بر ایجاد بلوکهای ساختمان شبکه عصبی تمرکز میکند
- مبتدی پسند بوده و دارای مجموعه دادههای از پیش برچسبگذاری شده است
- دارای لایههای از پیش تعریف شده، پارامترها و توابع پیش پردازش است
- SciKit-Learn (SKLearn)
- کتابخانه یادگیری ماشین منبع باز
- ساخته شده بر روی NumPy، SciPy و matplotlib
- دارای مجموعه دادههای داخلی، تقسیم دادهها و الگوریتم MLP است
- به دلیل عدم پشتیبانی از GPU برای یادگیری عمیق در مقیاس بزرگ نامناسب است
- Apache MXNet
- چارچوب یادگیری عمیق منبع باز
- از چندین CPU، GPU و زیرساخت ابری پویا پشتیبانی میکند
- قابلیت حمل برای استقرار در دستگاههای مختلف
- برنامهنویسی انعطافپذیر با گزینههای ضروری و نمادین
- Eclipse Deeplearning4j (DL4J)
- مجموعهای از ابزارهای یادگیری عمیق که روی JVM اجرا میشوند
- پشتیبانی از الگوریتمهای مختلف یادگیری عمیق
- ویژگیهای پشتیبانی Keras، Hadoop، CUDA، و ادغام Spark
- متلب
- نرم افزار اختصاصی با پشتیبانی از یادگیری عمیق
- هدف از کدنویسی حداقلی با ابزارها و برنامههای افزودنی مختلف است
- دارای برچسبگذاری تعاملی و استقرار خودکار
- Sonnet
- چارچوب یادگیری عمیق ساخته شده بر روی TensorFlow 2
- توسط محققان DeepMind توسعه یافته است
- سادگی و ادغام TensorFlow را ارائه میدهد
- Caffe
- چارچوب یادگیری عمیق منبع باز در ++C با Front-end پایتون
- متخصص در طبقهبندی و تقسیمبندی تصاویر
- Flux
- چارچوب یادگیری ماشین Julia برای خطوط لوله با عملکرد بالا
- دارای یک اینترفیس مبتنی بر انباشته لایه(layer stacking)
- از برنامهنویسی متمایز و کامپایل TPU پشتیبانی میکند
GPU و یادگیری عمیق
GPU (واحد پردازش گرافیکی) یک تراشه تخصصی است که پردازش گرافیک کامپیوتری را تسریع میکند. برخلاف CPU ها (واحدهای پردازش مرکزی) که وظایف را به صورت متوالی انجام میدهند، محاسبات GPU در پردازش موازی برتری دارد، به این معنی که میتواند بسیاری از محاسبات را به طور همزمان انجام دهد. این قابلیت پردازش موازی، GPU ها را برای محاسبات تکراری و لایهای که در الگوریتمهای یادگیری عمیق رایج است، ایده آل میکند.
پردازندههای گرافیکی همچنین دارای RAM ویدیویی اختصاصی (VRAM) با پهنای باند بسیار بالاتر از رم معمولی هستند که امکان انتقال سریعتر اطلاعات بین حافظه و هستههای پردازشی را فراهم میکند. این سرعت انتقال برای یادگیری عمیق بسیار مهم است، زیرا مدلها اغلب با تصاویر، ویدیوها یا مجموعه دادههای متنی بزرگ سروکار دارند. در نهایت، پردازندههای گرافیکی مدرن برای Deep Learning طراحی شدهاند، با ویژگیهایی مانند هستههای تانسور(tensor) که عملیات ماتریس خاصی را که در عملیات شبکه عصبی یافت میشود، تسریع میکنند.
مزایا و چالشهای یادگیری عمیق
یادگیری عمیق یک تکامل و پیشرفت در یادگیری ماشین است. با این حال، همیشه به روشهای سنتی دارای ارجحت نیست. درک مزایا و چالشها برای باز کردن پتانسیل کامل آن بسیار مهم است.
– فواید
در این بخش مزایایی از یادگیری عمیق مطرح میشود:
- سازگاری مداوم یک سیستم یادگیری عمیق بر اساس اطلاعات جدید سازگار و تکامل مییابد و محیطی پویا و پاسخگو را ایجاد میکند که پیچیدگی دنیای واقعی را منعکس میکند.
- تصمیمگیری خودکار: سیستمهای یادگیری عمیق نیاز به دخالت انسان را کاهش میدهد.
- دقت: مدلهای یادگیری عمیق در کارهایی مانند تشخیص تصویر، پردازش زبان طبیعی و تشخیص گفتار از یادگیری ماشینی سنتی پیشی میگیرند.
- یادگیری ویژگی: برخلاف روشهای سنتی که به ویژگیهای دستساز نیاز دارند، یادگیری عمیق بهطور خودکار ویژگیها را از دادهها یاد میگیرد، به طور بالقوه الگوهای پنهان را آشکار میکند و عملکرد مدل را بهبود میبخشد.
- تطبیق پذیری: یادگیری عمیق میتواند انواع مختلف داده از جمله تصاویر، متن، صدا و ویدئو را مدیریت کند.
– چالشها
برخی از چالشهای آموزش یک مدل یادگیری عمیق عبارتند از:
- برازش بیش از حد(Overfitting): تطبیق بیش از حد زمانی اتفاق میافتد که یک مدل دادههای آموزشی را خیلی خوب یاد بگیرد، نویز و جزئیاتی را که ممکن است به دادههای جدید و دیده نشده تعمیم ندهند، ضبط کند. یک مدل overfit شده در مجموعه آموزشی بیش از حد تخصصی میشود و توانایی خود را برای پیشبینی دقیق نمونههای ناشناخته و متنوع از دست میدهد.
- تقاضای منابع: آموزش مدلهای پیچیده Deep Learning از نظر محاسباتی گران است. به سخت افزار تخصصی و منابع انرژی قابل توجهی نیاز دارد. مدلهای یادگیری عمیق همچنین به مقادیر زیادی داده با کیفیت بالا برای آموزش مؤثر نیاز دارند که دستیابی به آن پرهزینه و زمانبر است.
- مشکل جعبه سیاه: با میلیونها پارامتر و معماری پیچیده، درک و تفسیر مدلهای یادگیری عمیق برای انسان چالش برانگیز است. به دلیل ماهیت جعبه سیاه آن، مهندسی معکوس و کشف چیزی که یک مدل یادگیری عمیق انجام داده است، دشوار است.
- Tunnel Vision: الگوریتمهای هوش مصنوعی بدون در نظر گرفتن پیامدهای گستردهتر، هدف خود را اولویتبندی میکنند که منجر به نتایج غیرمنتظره و نامطلوب میشود. برای مثال، پهپادی که برای به حداقل رساندن زمان تحویل بهینه شده است، ممکن است پرواز بر فراز مناطق ممنوعه را در اولویت قرار دهد.
فراتر از یادگیری عمیق
نقطه قوت اصلی Deep Learning، یادگیری مستقل از دادهها و فراتر رفتن از محدودیتهای از پیش برنامهریزی شده با حداقل ورودی انسانی است. مدلهای یادگیری عمیق که توسط مجموعه دادههای عظیم تغذیه میشوند، در تشخیص الگو و وظایف پیچیده برتری دارند و اغلب از عملکرد انسان پیشی میگیرند. با این حال، هوش واقعی از طیف وسیعتری از قابلیتها سرچشمه میگیرد که نظارت انسانی برای آنها حیاتی است. در واقع انسانها سوالات اخلاقی و درک دنیای واقعی را ارائه میکنند که توسعه هوش مصنوعی را هدایت میکند. همچنین انسانها مجموعه دادهها را تشریح میکنند، سوگیریها را شناسایی کرده و اطمینان حاصل میکنند که خروجیها با اهداف و ارزشهای انسانی همسو هستند. این همسویی بر رابطه همزیستی بین نبوغ انسان و هوش مصنوعی تاکید میکند.