
زمان تخمینی مطالعه: 11 دقیقه
تعریف پایگاه داده برداری
پایگاه داده برداری یک پایگاه داده است که اطلاعات را به صورت بردار ذخیره میکند، که نمایش عددی اشیاء دادهای است که به عنوان جاسازی برداری(Vector Embedding) نیز شناخته میشود. از قدرت جاسازیهای برداری برای فهرستبندی و جستجو در میان مجموعه دادههای عظیمی از دادههای بدون ساختار و دادههای نیمه ساختاریافته، مانند تصاویر، متن، یا دادههای حسگر استفاده میکند. در حالت کلی Vector Database برای مدیریت جاسازیهای برداری ساخته شدهاند و بنابراین راه حل کاملی برای مدیریت دادههای بدون ساختار و نیمه ساختار یافته ارائه میدهند.
یک پایگاه داده vector با کتابخانه جستجوی برداری یا نمایه برداری متفاوت است: این یک راه حل مدیریت داده است که ذخیرهسازی و فیلتر کردن ابردادهها را امکان پذیر میکند، مقیاس پذیر است، امکان تغییرات پویای دادهها، انجام پشتیبان گیری، و ارائه ویژگیهای امنیتی را فراهم میکند. یک پایگاه داده برداری دادهها را از طریق بردارهای با ابعاد بالا سازماندهی میکند. بردارهای با ابعاد بالا شامل صدها بعد هستند و هر بعد مربوط به ویژگی یا ویژگی خاصی از شی دادهای است که نشان میدهد.
جاسازیهای برداری Vector Embedding چیست؟
جاسازیهای برداری یک نمایش عددی از یک موضوع، کلمه، تصویر یا هر قطعه داده دیگری است. جاسازیهای برداری که به عنوان جاسازی نیز شناخته میشوند، توسط مدل زبانی بزرگ و سایر مدلهای هوش مصنوعی ایجاد میشوند. فاصله بین هر جاسازی برداری چیزی است که یک پایگاه داده برداری یا یک موتور جستجوی برداری را قادر میسازد تا شباهت بین بردارها را تعیین کند. فاصلهها ممکن است ابعاد مختلفی از اشیاء داده را نشان دهند که یادگیری ماشین و درک هوش مصنوعی از الگوها، روابط و ساختارهای زیربنایی را ممکن میسازد.
پایگاه داده برداری چگونه کار میکند؟
یک پایگاه داده برداری با استفاده از الگوریتمهایی برای فهرستبندی و پرس و جوی جاسازیهای برداری کار میکند. الگوریتمها جستجوی تقریبی نزدیکترین همسایه (ANN) را از طریق هش کردن، کوانتیزه کردن، یا جستجوی مبتنی بر نمودار فعال میکنند. برای بازیابی اطلاعات، یک جستجوی ANN نزدیکترین همسایه برداری یک پرس و جو را پیدا میکند. از نظر محاسباتی هزینه کمتر از جستجوی kNN (الگوریتم نزدیکترین همسایه شناخته شده، یا الگوریتم k واقعی نزدیکترین همسایه)، جستجوی تقریبی نزدیکترین همسایه(ANN)همچنین دارای دقت کمتری به نسبت KNN است. با این حال، برای مجموعه دادههای بزرگ بردارهای با ابعاد بالا کارآمد و در مقیاس بزرگ خوب کار میکند.خط لوله پایگاه داده برداری به شکل زیر است:
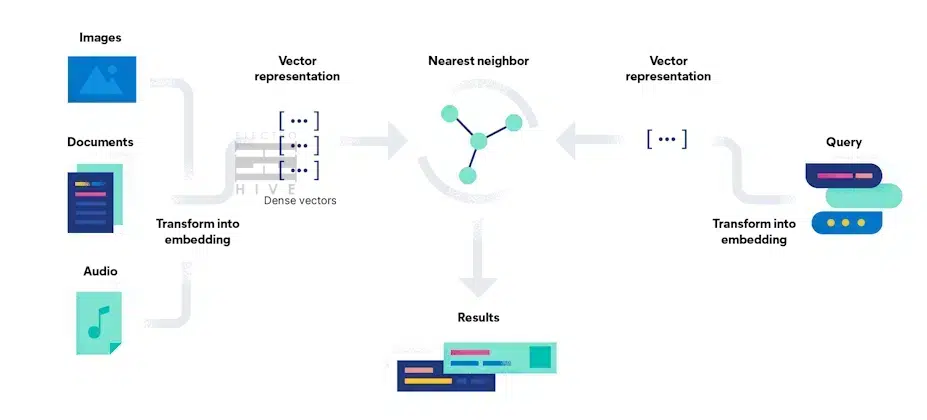
- نمایه سازی(Indexing): با استفاده از تکنیکهای هش، کوانتیزه کردن یا گراف، یک پایگاه داده برداری، بردارها را با نگاشت آنها به یک ساختار داده مشخص index میکند. این امکان جستجوی سریعتر را فراهم میکند.
- هش کردن(Hashing): یک الگوریتم هش، مانند الگوریتم locality-sensitive hashing (LSH)، بهترین گزینه برای جستجوی تقریبی نزدیکترین همسایه است زیرا نتایج سریع را فعال میکند و نتایج تقریبی ایجاد میکند. LSH از جداول هش برای نقشه برداری از نزدیکترین همسایگان استفاده میکند. یک پرس و جو در یک جدول هش میشود و سپس با مجموعهای از بردارها در همان جدول مقایسه میشود تا شباهتها مشخص شود.
- کوانتیزه کردن(Quantization): یک تکنیک کوانتیزاسیون، مانند کوانتیزه کردن محصول (product quantization)، بردارها را به قطعات کوچکتر تقسیم میکند و آن قسمتها را با کد نشان میدهد و سپس قطعات را دوباره کنار هم قرار میدهد. نتیجه نمایش کد یک بردار و اجزای آن است. مجموعه این کدها به عنوان کتاب کد شناخته میشود. هنگامی که پرس و جو میشود، یک پایگاه داده برداری که از کوانتیزاسیون استفاده میکند، پرس و جو را به کد تقسیم میکند و سپس آن را با کتاب کد مطابقت میدهد تا شبیهترین کد را برای تولید نتایج پیدا کند.
- مبتنی بر گراف(Graph-based): یک الگوریتم گراف، مانند الگوریتم Hierarchical Navigable Small World (HNSW) از گرهها برای نمایش بردارها استفاده میکند. این روش گرهها را خوشهبندی کرده و خطوط یا لبههایی را بین گرههای مشابه ترسیم میکند و نمودارهای سلسله مراتبی ایجاد میکند. هنگامی که یک پرس و جو راه اندازی میشود، الگوریتم سلسله مراتب نمودار را برای یافتن گرههای حاوی بردارهایی که شبیهترین بردار پرس و جو هستند، هدایت میکند.
یک پایگاه داده برداری نیز فراداده یک شی داده را index میکند. به همین دلیل، یک پایگاه داده برداری دارای دو شاخص است: یک نمایه برداری و یک نمایه ابرداده.
- Querying: هنگامی که یک پایگاه داده برداری یک پرس و جو دریافت میکند، بردارهای نمایه شده را با بردار پرس و جو مقایسه میکند تا نزدیک ترین همسایگان بردار را تعیین کند. برای ایجاد نزدیکترین همسایگان، یک پایگاه داده برداری بر روشهای ریاضی موسوم به اندازهگیریهای شباهت تکیه میکند. انواع مختلفی از معیارهای شباهت وجود دارد:
- شباهت کسینوس: شباهت را در محدوده 1- تا 1 ایجاد میکند. با اندازهگیری کسینوس زاویه بین دو بردار در یک فضای برداری، بردارهایی را تعیین میکند که به صورت قطری متضاد (نمایش 1-)، متعامد (نمایش با 0) یا یکسان (با 1 نشان داده شده است) هستند.
- فاصله اقلیدسی با اندازهگیری فاصله خط مستقیم بین بردارها شباهت را در محدوده 0 تا بینهایت تعیین میکند. بردارهای یکسان با 0 نشان داده میشوند، در حالی که مقادیر بیشتر نشان دهنده تفاوت بیشتر بین بردارها است.
- ضرب نقطهای تشابه بردار را در محدوده منهای بینهایت تا بینهایت تعیین میکنند. با اندازهگیری حاصل ضرب بزرگی دو بردار و کسینوس زاویه بین آنها، حاصل ضرب نقطهای مقادیر منفی به بردارهایی که از یکدیگر دور هستند، 0 به بردارهای متعامد و مقادیر مثبت به بردارهایی که در یک جهت هستند، اختصاص میدهد.
- پس پردازش: مرحله نهایی در خط لوله پایگاه داده vector گاهی اوقات پس پردازش یا پس از فیلتر است، که طی آن دیتابیس برداری از معیار مشابهت متفاوتی برای رتبهبندی مجدد نزدیکترین همسایگان استفاده میکند. در این مرحله، پایگاه داده نزدیکترین همسایگان پرس و جو شناسایی شده در جستجو را بر اساس ابرداده آنها فیلتر میکند.برخی از پایگاههای داده برداری ممکن است قبل از اجرای جستجوی برداری از فیلترها استفاده کنند. در این مورد به آن پیش پردازش یا پیش فیلترینگ گفته میشود.
چرا پایگاه داده های برداری مهم هستند؟
پایگاه دادههای برداری مهم هستند زیرا جاسازیهای برداری را در خود نگه میدارند و مجموعهای از قابلیتها از جمله نمایهسازی، معیارهای فاصله و جستجوی شباهت را فعال میکنند. به عبارت دیگر، پایگاههای داده برداری برای مدیریت دادههای بدون ساختار و دادههای نیمه ساختار یافته تخصصی هستند. در نتیجه، پایگاههای داده برداری ابزاری حیاتی در یادگیری ماشینی و چشم انداز دیجیتالی هوش مصنوعی هستند.
اجزای اصلی پایگاههای داده برداری
یک پایگاه داده برداری ممکن است دارای اجزای اصلی زیر باشد:
- عملکرد و تحمل خطا: فرآیندهای تقسیم و تکرار تضمین میکند که یک پایگاه داده برداری عملکرد و تحمل خطاها را دارد. تقسیم(sharding) شامل پارتیشنبندی دادهها در چندین گره است، در حالی که تکثیر شامل ساخت چندین نسخه از دادهها در گرههای مختلف است. در صورت خرابی یک گره، این امکان تحمل خطا و ادامه عملکرد را فراهم میکند.
- قابلیتهای نظارت: برای اطمینان از عملکرد و تحمل خطا، یک پایگاه داده برداری نیاز به نظارت بر استفاده از منابع، عملکرد پرس و جو و سلامت کلی سیستم دارد.
- قابلیتهای کنترل دسترسی: پایگاههای داده برداری نیز به مدیریت امنیت دادهها نیاز دارند. مقررات کنترل دسترسی، انطباق، پاسخگویی، و توانایی ممیزی استفاده از پایگاه داده را تضمین میکند. این همچنین به این معنی است که دادهها محافظت میشوند: افرادی که مجوزها را دارند به آن دسترسی پیدا میکنند و سابقه فعالیت کاربر حفظ میشود.
- مقیاسپذیری و تنظیم پذیری: قابلیتهای کنترل دسترسی خوب بر مقیاسپذیری و تنظیم پذیری دیتابیس برداری تأثیر میگذارد. با افزایش مقدار دادههای ذخیره شده، امکان مقیاس افقی اجباری میشود. نرخهای مختلف درج و پرس و جو، و همچنین تفاوت در سخت افزار اساسی، بر نیازهای برنامه تاثیر میگذارد.
- کاربران چندگانه و جداسازی دادهها: در کنار مقیاسپذیری و قابلیتهای کنترل دسترسی، یک پایگاه داده برداری باید چندین کاربر یا چند اجارهای را در خود جای دهد. در هماهنگی با این، پایگاههای داده برداری باید جداسازی دادهها را فعال کنند تا هرگونه فعالیت کاربر (مانند درج، حذف، یا پرس و جو) برای سایر کاربران خصوصی باقی بماند – مگر اینکه نیاز باشد.
- پشتیبانگیری: پایگاههای داده برداری، پشتیبانگیری منظم از دادهها ایجاد میکنند. این یک جزء کلیدی از یک پایگاه داده برداری در صورت خرابی سیستم است – در صورت از دست رفتن داده یا خرابی دادهها، پشتیبانگیری میتواند به بازگرداندن پایگاه داده به حالت قبلی کمک کند. این باعث میشود که زمان از کار افتادگی به حداقل برسد.
- API ها و SDK ها: یک پایگاه داده برداری از API ها برای فعال کردن یک رابط کاربر پسند استفاده میکند. API یک رابط برنامهنویسی کاربردی یا نوعی نرمافزار است که برنامهها را قادر میسازد از طریق درخواستها و پاسخها با یکدیگر صحبت کنند. لایههای API تجربه جستجوی برداری را ساده میکند. SDK ها یا کیتهای توسعه نرم افزار، اغلب API ها را بستهبندی میکنند. آنها زبانهای برنامه نویسی هستند که پایگاه داده برای برقراری ارتباط و مدیریت از آنها استفاده میکند. SDK ها به برنامه نویس برای استفاده از پایگاههای داده برداری کمک میکنند زیرا در هنگام توسعه موارد استفاده خاص (جستجوی معنایی، سیستمهای توصیه و غیره) نیازی به نگرانی در مورد ساختار اساسی ندارند.
تفاوت بین پایگاه داده برداری و پایگاه داده سنتی چیست؟
یک پایگاه داده سنتی اطلاعات را به شکل جدولی ذخیره میکند و با اختصاص مقادیر به نقاط داده، دادهها را نمایه میکند. و هنگامی که پرس و جو انجام میشود، یک پایگاه داده سنتی نتایجی را برمیگرداند که دقیقاً با پرس و جو مطابقت دارند. اما یک دیتابیس برداری، بردارها را به شکل جاسازی ها ذخیره میکند و جستجوی برداری را فعال میکند، که نتایج پرس و جو را بر اساس معیارهای شباهت (به جای مطابقت دقیق) برمیگرداند. یک پایگاه داده برداری در جایی که یک پایگاه داده سنتی ناتوان است به شما کمک میکند: پایگاه داده برداری به طور عمدی برای کار با جاسازیهای برداری طراحی شده است.
یک پایگاه داده برداری همچنین در کاربردهای خاص مانند جستجوی مشابه، هوش مصنوعی و برنامه های یادگیری ماشین مناسب تر از پایگاه داده سنتی است، زیرا جستجوی با ابعاد بالا و نمایهسازی سفارشی را امکان پذیر میکند و به دلیل مقیاسپذیر، انعطاف پذیر و کارآمد است.
کاربردهای پایگاه داده برداری
پایگاه دادههای برداری در هوش مصنوعی، یادگیری ماشین (ML)، پردازش زبان طبیعی (NLP) و برنامههای کاربردی تشخیص تصویر استفاده میشود.
- برنامههای کاربردی AI/ML: یک پایگاه داده برداری میتواند قابلیتهای هوش مصنوعی را با بازیابی اطلاعات معنایی و حافظه بلند مدت بهبود بخشد.
- برنامههای کاربردی NLP: جستجوی شباهت برداری، جزء کلیدی پایگاههای داده برداری، برای برنامههای کاربردی پردازش زبان طبیعی مفید است. یک پایگاه داده برداری میتواند جاسازیهای متن را پردازش کند، که به رایانه امکان میدهد زبان انسانی – یا طبیعی – را “درک” کند.
- برنامههای کاربردی بازیابی و شناسایی تصویر: پایگاههای داده برداری تصاویر را به جاسازی تصویر تبدیل میکند. با جستجوی شباهت، آنها قادر به بازیابی تصاویر مشابه یا شناسایی تصاویر مشابه هستند.
پایگاه دادههای برداری همچنین میتوانند به برنامههای تشخیص ناهنجاری و تشخیص چهره خدمت کنند.
روندهای آینده در پایگاه دادههای برداری
آینده پایگاههای داده برداری به طور پیچیدهای با توسعه هوش مصنوعی و ML و همچنین تحقیقات مربوط به استفاده از یادگیری عمیق برای ایجاد جاسازیهای قویتر برای دادههای ساختاریافته و بدون ساختار مرتبط است. با بهبود توانایی ایجاد جاسازیهای بهتر، توانایی یک دیتابیس برداری برای پردازش و مدیریت بهتر این جاسازیها نیازمند تکنیکها و الگوریتمهای جدید است. در واقع، چنین روشهای جدیدی به طور مداوم در حال توسعه هستند. تحقیقات اضافی به توسعه پایگاههای داده ترکیبی اختصاص داده شده است. اینها در نظر گرفته شدهاند تا قدرت پایگاه دادههای سنتی رابطهای و پایگاههای داده برداری را به عنوان پاسخی به نیاز روزافزون به پایگاههای داده کارآمد و مقیاس پذیر ترکیب کنند.